Digital Operational Resilience Act: Umsetzung von DORA leicht gemacht
Die Umsetzung des Digital Operational Resilience Act (DORA) stellt Finanzunternehmen und ihre IKT-Dienstleister vor neue Herausforderungen. Diese Verordnung zielt darauf ab, die digitale Resilienz zu stärken und sicherzustellen, dass Unternehmen in der Lage sind, auf IKT-bezogene Störungen und Bedrohungen effektiv zu reagieren. In diesem Blogbeitrag bieten wir Ihnen eine Übersicht über die wichtigsten Schritte und Maßnahmen zur erfolgreichen Umsetzung von DORA.
DORA Cheat Sheet: Vertragsprüfung für IKT-Drittparteirisiken
Inhaltsverzeichnis
1. IKT-Risikomanagement implementieren
Ein robustes IKT-Risikomanagementsystem ist das Herzstück von DORA. Hier sind die wesentlichen Schritte:
- Risikoidentifikation: Identifizieren Sie alle potenziellen IKT-Risiken, die Ihr Unternehmen betreffen könnten.
- Risikobewertung: Bewerten Sie die identifizierten Risiken hinsichtlich ihrer Wahrscheinlichkeit und potenziellen Auswirkungen.
- Risikominderung: Entwickeln und implementieren Sie Maßnahmen zur Minderung der identifizierten Risiken.
- Überwachung und Überprüfung: Überwachen Sie kontinuierlich die Risiken und überprüfen Sie regelmäßig die Wirksamkeit Ihrer Risikominderungsmaßnahmen.
2. Management von IKT-Drittparteirisiken
Die Zusammenarbeit mit Drittanbietern birgt zusätzliche Risiken. Folgende Punkte sind zu beachten:
- Vertragsprüfung: Stellen Sie sicher, dass alle Verträge mit Drittanbietern klare Bestimmungen zur IKT-Sicherheit und Resilienz enthalten.
- Due Diligence: Führen Sie eine gründliche Überprüfung der IKT-Sicherheitspraktiken Ihrer Drittanbieter durch.
- Kontinuierliche Überwachung: Überwachen Sie regelmäßig die Leistung und Sicherheit Ihrer Drittanbieter.´
3. Meldung von IKT-bezogenen Vorfällen
Eine schnelle und effektive Reaktion auf IKT-Vorfälle ist entscheidend:
- Vorfallserfassung: Entwickeln Sie ein System zur Erfassung aller IKT-bezogenen Vorfälle.
- Vorfallanalyse: Analysieren Sie die Vorfälle, um die Ursachen zu identifizieren und Maßnahmen zur Vermeidung zukünftiger Vorfälle zu entwickeln.
- Meldung: Melden Sie schwerwiegende Vorfälle unverzüglich an die zuständigen Behörden gemäß den DORA-Vorgaben.
4. Testen der digitalen operationellen Resilienz
Regelmäßige Tests sind unerlässlich, um die Widerstandsfähigkeit Ihres Unternehmens zu gewährleisten:
- Situationsanalysen: Erwägen Sie, situative Analysen durchzuführen, um die Effizienz Ihrer Reaktionsprozesse bei IKT-Störungen einzuschätzen.
- Sicherheitsüberprüfungen: Es könnte hilfreich sein, gelegentlich externe Experten hinzuzuziehen, um Ihre Systeme auf eventuelle Schwachstellen zu überprüfen.
- Schwachstellenbehebung: Beheben Sie identifizierte Schwachstellen umgehend und aktualisieren Sie Ihre Sicherheitsmaßnahmen.
5. Informationsaustausch unter Finanzunternehmen
Der Austausch von Informationen über Bedrohungen und Vorfälle kann die kollektive Resilienz stärken:
- Netzwerke und Plattformen: Nutzen Sie Netzwerke und Plattformen zum Austausch von Informationen über IKT-Bedrohungen und -Vorfälle.
- Best Practices: Teilen Sie Best Practices und Lessons Learned mit anderen Unternehmen, um gemeinsam die Resilienz zu erhöhen.
6. Dokumentation und Berichterstattung
Eine gründliche Dokumentation und regelmäßige Berichterstattung sind unerlässlich:
- Dokumentation: Dokumentieren Sie alle Maßnahmen, die Sie zur Umsetzung von DORA ergreifen.
- Berichterstattung: Erstellen Sie regelmäßige Berichte für das Management und die zuständigen Behörden über den Fortschritt und die Ergebnisse Ihrer Maßnahmen.
Unterstützung durch Künstliche Intelligenz (KI)
Die Umsetzung von DORA kann komplex sein, aber mit den richtigen Werkzeugen und Partnern können Sie die Anforderungen effektiv erfüllen. Tucan.ai bietet innovative Lösungen zur Vertragsanalyse und -prüfung, die Ihnen helfen, sicherzustellen, dass Ihre Verträge den DORA-Anforderungen entsprechen. Nutzen Sie die KI-gestützte Technologie von Tucan.ai, um Zeit und Ressourcen zu sparen und mögliche Risiken frühzeitig zu erkennen und zu beheben.
DORA Cheat Sheet: Vertragsprüfung für IKT-Drittparteirisiken
Sorgfältige Planung und Druchführung
Die erfolgreiche Umsetzung von DORA erfordert eine sorgfältige Planung und Durchführung. Indem Sie die oben genannten Schritte befolgen, können Sie sicherstellen, dass Ihr Unternehmen gut vorbereitet ist, um den neuen Anforderungen gerecht zu werden und die digitale Resilienz zu stärken. Nutzen Sie die Unterstützung von Tucan.ai, um Ihre Verträge und Prozesse zu überprüfen und sicherzustellen, dass Sie den neuen Vorschriften entsprechen.
Über Tucan.ai
Tucan.ai ist ein führender Anbieter im Bereich Legal-Tech und bietet innovative Lösungen zur Vertragsanalyse und -prüfung. Mit der KI-gestützten Technologie von Tucan.ai können Sie Zeit und Ressourcen sparen und sicherstellen, dass Ihre Verträge den neuesten gesetzlichen Anforderungen entsprechen.
Bleiben Sie vorbereitet und sichern Sie die digitale Zukunft!
DORA: Der Digital Operational Resilience Act – Was Sie wissen müssen
Die digitale Transformation bringt viele Vorteile, aber auch Herausforderungen mit sich, insbesondere für Finanzunternehmen und deren IKT-Dienstleister. Um die Widerstandsfähigkeit gegen digitale Risiken zu erhöhen, hat die EU den Digital Operational Resilience Act (DORA) eingeführt. DORA tritt am 17. Januar 2025 in Kraft und stellt sicher, dass Finanzunternehmen und ihre Dienstleister auf digitale Angriffe und Störungen vorbereitet sind. In diesem Blogbeitrag erklären wir Ihnen, worum es bei DORA geht und was Sie beachten müssen.
Inhaltsverzeichnis
Was ist DORA?
DORA ist eine EU-Verordnung, die darauf abzielt, die digitale operationelle Resilienz von Finanzunternehmen und deren IKT-Dienstleistern zu stärken. Ziel ist es, die Fähigkeit dieser Organisationen zu verbessern, auf alle Arten von IKT-bezogenen Störungen und Bedrohungen zu reagieren und sich davon zu erholen.
Wen betrifft DORA?
DORA betrifft eine Vielzahl von Finanzunternehmen, darunter:
- Kreditinstitute
- Zahlungsinstitute
- Wertpapierfirmen
- Versicherungsunternehmen
- Fondsverwaltungsgesellschafte
- Börsen und Handelsplattformen
WICHTIG: Auch IKT-Dienstleister, die diese Unternehmen unterstützen, fallen unter DORA.
Wichtige Anforderungen von DORA
1. IKT-Risikomanagement
- Finanzunternehmen müssen ein robustes IKT-Risikomanagementsystem einführen.
- Identifizierung, Bewertung und Minderung von IKT-Risiken sind essenziell.
- Regelmäßige Überprüfung und Aktualisierung der IKT-Risikomanagementstrategien.
2. Management von IKT-Drittparteirisiken
- Finanzunternehmen müssen sicherstellen, dass auch ihre Drittanbieter und Dienstleister den DORA-Anforderungen entsprechen.
- Verträge mit Drittanbietern sollten Bestimmungen zur IKT-Sicherheit und Resilienz enthalten.
3. Meldung von IKT-bezogenen Vorfällen
- Finanzunternehmen müssen schwerwiegende IKT-Vorfälle unverzüglich an die zuständigen Behörden melden.
- Ein systematischer Ansatz zur Erfassung, Analyse und Meldung von Vorfällen ist erforderlich.
4. Testen der digitalen operationellen Resilienz
- Regelmäßige Tests der Widerstandsfähigkeit gegen IKT-Störungen und Angriffe sind vorgeschrieben.
- Simulationsübungen und Penetrationstests sollten durchgeführt werden, um Schwachstellen zu identifizieren und zu beheben.
5. Informationsaustausch unter Finanzunternehmen
- Förderung des Austauschs von Informationen über Bedrohungen und Vorfälle zwischen Finanzunternehmen.
- Zusammenarbeit zur Stärkung der kollektiven Resilienz der Branche.
Umsetzung von DORA
Die Umsetzung von DORA kann komplex sein, aber mit den richtigen Werkzeugen und Partnern können Sie die Anforderungen effektiv erfüllen. Hier kommt Tucan.ai ins Spiel. Mit Tucan.ai können Sie Verträge auf DORA-spezifische Anforderungen prüfen und sicherstellen, dass Ihre Vereinbarungen mit Drittanbietern den gesetzlichen Vorgaben entsprechen. Tucan.ai bietet eine intelligente Lösung zur Vertragsanalyse und hilft Ihnen, mögliche Risiken frühzeitig zu erkennen und zu beheben.
Frühzeitige Vorbereitung
DORA stellt eine bedeutende Veränderung für Finanzunternehmen und ihre IKT-Dienstleister dar. Es ist entscheidend, frühzeitig mit der Vorbereitung zu beginnen, um die Anforderungen rechtzeitig zu erfüllen und die digitale Resilienz zu stärken. Nutzen Sie Tools wie Tucan.ai, um Ihre Verträge und Prozesse zu überprüfen und sicherzustellen, dass Sie den neuen Vorschriften entsprechen.
DORA Cheat Sheet: Vertragsprüfung für IKT-Drittparteirisiken
Über Tucan.ai
Tucan.ai ist ein führender Anbieter im Bereich Legal-Tech und bietet innovative Lösungen zur Vertragsanalyse und -prüfung. Mit der KI-gestützten Technologie von Tucan.ai können Sie Zeit und Ressourcen sparen und sicherstellen, dass Ihre Verträge den neuesten gesetzlichen Anforderungen entsprechen.
Bleiben Sie vorbereitet und sichern Sie die digitale Zukunft!
Von Daten zu Insights: KI-Geheimnisse für Marktforschungs-Profis
In einer Zeit, in der Daten das A und O sind, revolutioniert die Integration von künstlicher Intelligenz (KI) in die Marktforschung die Art und Weise, wie wir Erkenntnisse gewinnen und interpretieren. In seinem letzten Webinar "Von Daten zu Insights: KI-Geheimnisse für Marktforschungs-Profis", bot Florian Polak, Mitgründer von Tucan.ai, einen tiefen Einblick in die praktischen Anwendungen von KI in der Marktforschung. Dieser Blogbeitrag bietet eine ausführliche Zusammenfassung des Webinars auf martforschung.de und beleuchtet die Vorteile, die KI-Lösungen für die Branche bringen können.
"Wir wissen, wie wichtig die Transparenz und Zuverlässigkeit der von unserer KI gelieferten Ergebnisse ist."

Interview Marktforschung.de mit Florian Polak
Geschäftsführer, Tucan.ai GmbH
Edit Content
Edit Content
– Tucan.ai ist ein junges Unternehmen aus Berlin, spezialisiert auf die Extraktion relevanter Informationen aus Text-, Audio- und Videodateien für Marktforschungszwecke.KI-Systeme und Anwendungen:
– Es wurde ein Überblick über KI-Systeme und deren Anwendung in der Marktforschung gegeben, inklusive Tipps und Tricks für den effizienten Einsatz.
– Tucan.ai bietet Produkte an, die es ermöglichen, KI-Technologien zur Effizienzsteigerung und zur Überholung der Konkurrenz einzusetzen.
Probleme und Lösungen bei KI-Systemen:
– Diskussion über gängige Probleme bei der Nutzung von KI-Systemen, insbesondere das Phänomen der “Halluzination” von KI, ungenaue oder oberflächliche Antworten und Datenschutzbedenken.
– Tucan.ai nutzt spezielle Technologien und Ansätze, um präzise und relevante Ergebnisse zu liefern und gleichzeitig Datenschutz und Sicherheit zu gewährleisten.
Anwendungsbereiche und Funktionen:
– Tucan.ai’s Software ermöglicht die Auswertung von Online-Communities, qualitative Kodierung von Interviews oder Gruppenstudien und quantitative Auswertung von Textdaten.
– Die Software unterstützt verschiedene Datenformate und bietet eine hohe Verarbeitungsgeschwindigkeit und Genauigkeit.
Datenschutz und Sicherheit:
– Tucan.ai garantiert, dass Daten ausschließlich in Deutschland verarbeitet werden und bietet verschiedene Kooperationsmodelle an, einschließlich On-Premise-Lösungen.
Preismodelle:
– Tucan.ai bietet flexible Preismodelle an, die auf Projektbasis oder als jährliche Pauschale gestaltet werden können, abhängig von den Bedürfnissen des Kunden.
Fragen und Antworten:
– Im Webinar wurden verschiedene Fragen der Teilnehmer beantwortet, unter anderem zur Verarbeitung von Dialekten, der Möglichkeit, Audiodateien zu testen, und zur Verarbeitung und Analyse von demografischen Daten in Verbindung mit offenen Antworten.
Abschluss:
– Das Webinar endete mit dem Angebot, bei weiteren Fragen Kontakt aufzunehmen und der Ankündigung, dass eine Zusammenfassung des Webinars zur Verfügung gestellt wird.
Edit Content
Schönen guten Tag. Hallo. Florian Polak ist mein Name hier von Tucan.ai. Willkommen bei unserem Webinar zur Woche der Marktforschung von Tucan.ai. Ich glaube, wir können schon anfangen. Ich werde Ihnen ganz kurz nur den Ablauf erklären. Ich werde Ihnen einen Überblick geben zu verschiedenen Themen im Rahmen der CI Forschung. Natürlich. Ähm, wir werden im Anschluss. Ich glaube, ich schätze mal, dass ich so 20 30 Minuten maximal brauchen werde. Wenn werden im Anschluss auch eine Fragerunde machen. Haben Sie in der Zwischenzeit Fragen? Bitte schreiben Sie die in unseren Chat einfach hinein und am Schluss, im Anschluss des Webinars, werde ich natürlich alle Fragen beantworten, die Sie im Chat gestellt haben.Florian Polak: 00:00:42,400 –> 00:01:21,640
Wunderbar. Dann würde ich ganz kurz anfangen. Vielleicht ganz kurz zu mir. Florian Polak hier. Ich bin einer der Geschäftsführer von Tucan.ai. Mein Job, abgesehen davon Webinare zu halten, ist es mehr oder weniger eigentlich zu übersetzen, was unsere technische Abteilung alles macht. Wir sind ein junges Unternehmen aus Berlin, die mittlerweile seit fünf Jahren am Markt und haben uns darauf fokussiert, gerade im Bereich Marktforschung relevante Informationen aus einer großen Menge von Text oder auch aus Audio oder Videodateien im Prinzip zu extrahieren. Ich werde Ihnen einen kurzen Überblick jetzt mal geben. Wunderbar, wir fangen auch schon an, was werde ich in diesem Webinar alles machen?Florian Polak: 00:01:22,360 –> 00:01:57,730
Ich werde ein bisschen eingehen auf KI Systeme und Begrifflichkeiten da drin in Ihnen versuchen simpel einen Überblick zu geben. Ohne jetzt zu sehr in die Details hier reinzugehen. Ich werde Ihnen vor allem aber auch ein paar Tipps und Tricks auf den Weg geben, worauf Sie vielleicht beim Arbeiten mit KI auch achten sollten. Und ich werde Ihnen natürlich auch zeigen, was wir grundsätzlich für Produkte anbieten und wie Sie entweder mit uns oder auch das selber im Prinzip aufbauen können, dass Sie KI Technologien bei Ihnen einsetzen und im Prinzip damit natürlich sehr, sehr effizient ihre Konkurrenz im Prinzip abhängen können.
Florian Polak: 00:01:59,660 –> 00:02:29,660
Was ist auf der Agenda? Hier eine kurze Vorstellungsrunde zu uns machen, was wir so machen, was wir grundsätzlich anbieten. Ich werde dann vor allem aber auch einen Fokus darauf legen, was für Probleme mit KI Systemen eigentlich sind, sondern was man da eigentlich ein bisschen achten sollte. Ich werde ein bisschen darauf eingehen, wie so grundsätzlich der Markt aktuell agiert und was gut daran ist und was vielleicht nicht so gut daran ist. Dann gebe ich Ihnen natürlich auch einen Überblick über unsere Software und werde Ihnen auch verraten, im Prinzip, was hinter unserem System steckt, wie wir das Ganze im Prinzip aufgebaut haben.
Florian Polak: 00:02:30,260 –> 00:03:08,210
Um Ihnen einfach nochmal einen Überblick zu geben, warum unser System in diesem Fall sehr gut geeignet ist für die Marktforschung. Dann natürlich zu guter Letzt noch ein kleines Thema über das Thema Datenschutz natürlich. Und Sicherheit ist sehr wichtig, gerade in der Auswertung von Studien und natürlich, was wir grundsätzlich für Preispakete haben, damit Sie den Überblick haben. Zu guter Letzt eine Fragerunde, wo sich alle Ihre Fragen beantworten werde, die Sie in diesem Chat stellen. Dann fangen wir auch schon kurz mal an, wir würden grundsätzlich in 2019 gegründet, sind ein Kleinunternehmen aus Berlin, haben mittlerweile 20 Mitarbeiter, ein Großteil davon natürlich in der Technikabteilung.
Florian Polak: 00:03:09,050 –> 00:03:51,800
Haben da eigene KI Spezialisten, die sich in den letzten vier, fünf Jahren eigentlich damit beschäftigt haben, solche Algorithmen und aber auch natürlich Infrastruktur dafür aufzubauen, mit dem Fokus immer mehr einer Analyse von Gesprächen, aber auch Texten gut hinbekommen. Wir haben uns fokussiert, Da wir ja als deutsches Unternehmen mit auch sehr öffentlichen oder sehr großen Unternehmen zusammenarbeiten, haben wir uns darauf fokussiert, eben auf sensible Informationen zu verarbeiten mit dem entsprechenden Sicherheits und Datenschutzstandards, die damit einhergehen, und haben hier aber auch in der Marktforschung mittlerweile auch recht große Kunden. Was kann man mit unserer Software machen? Ganz grob gesagt sind es drei Bereiche.
Florian Polak: 00:03:52,010 –> 00:04:38,180
Das eine ist im Prinzip Online Communities auswerten, das heißt wirklich Fragen an große Datenmenge zu stellen. Dann natürlich die qualitative Kodierung von Kern, von Interviews oder Gruppenstudien und natürlich auch vor allem bei frei Textnennungen, also Textdaten, im Prinzip Excel oder Textdateien quantitativ im Prinzip auszuwerten, wann immer Sie eine Freitagsnennung haben, das möglich auf einen einzelnen Code zu verdichten und dann im Prinzip das Ganze auszuwerten. Ähm, ja, grundsätzlich unsere. Wir haben einige Kunden hier in Deutschland mittlerweile die größten, die wir haben, ist einerseits die deutsche Bundeswehr, aber auch im Automobilsektor. Recht viel ist mittlerweile mit Porsche und Mercedes Benz und im öffentlichen Bereich vor allem auch natürlich Landtag.
Florian Polak: 00:04:38,180 –> 00:05:18,290
Mecklenburg Vorpommern ist einer unserer größten Kunden hier. Grundsätzlich die drei Bereiche. Was kann man da genau machen? Im qualitativen Forschungsbereich geht es vor allem darum, Interviews oder Gruppendiskussionen im Prinzip zu einerseits zu transkribieren, da damit haben wir ursprünglich mal angefangen haben eigene Spracherkennungsalgorithmen aufgebaut, wie Sie es vielleicht hören. Ich bin Österreicher, der auch verschiedene. Im Prinzip Akzente und Dialekte kann unser Algorithmus ganz gut verstehen. Das Ganze wird in Text gebracht und dann geht es darum, im Prinzip anhand eines Leitfadens oder Ihrer Fragen im Prinzip relevante Antworten zu extrahieren und zusammenzufassen und wieder zu verdichten. Das selbe Thema dann auch in der quantitativen Forschung.
Florian Polak: 00:05:18,290 –> 00:05:56,180
Hier geht es vor allem darum, dass man wirklich große Mengen von Antworten hat, also beispielsweise Kundenservice ist ein klassischer Fall, wo dann sehr, sehr viele Antworten in alle Richtungen natürlich gehen, wo man diese Textendungen dann verdichtet, im Prinzip mit einem entweder bestehenden Codeplan oder aber auch die KI tatsächlich selber Code Pläne finden zu lassen. Im Durchschnitt braucht es unser System für so circa 1000 Freitagsnennungen unter zwei Minuten. Das geht also relativ fix. Das Ganze dann natürlich die Community so auswerten. Da geht es dann darum, dass wir viele, viele verschiedene Daten haben. Also sie können diese Daten entweder bei Excel hochladen oder aber auch per API Schnittstelle mit unserem System.
Florian Polak: 00:05:56,720 –> 00:06:38,450
Und dann können Sie Fragen im Prinzip an diese Datenmengen stellen, um dann relevante Ergebnisse im Prinzip zu extrahieren. Mehr dazu ein bisschen später. Verschiedenste Formate funktionieren bei uns Audio Videodateien, Excel wie schon erwähnt bzw. Maschinen lesbarer Text kann angeschlossen werden. Das Ganze natürlich auch eben als Schnittstelle mit Ihrem System. Wir haben ein paar Garantien, die wir Ihnen geben. Das eine Thema ist Anti Halluzination, da komme ich gleich nachher noch kurz darauf zu sprechen, was das eigentlich ist und wie man das dagegenstellen kann, dass wir im Prinzip ihnen helfen, eigentlich, dass unsere KI die relevanten Ergebnisse aus den Textmengen oder Datenmengen auch extrahiert.
Florian Polak: 00:06:38,900 –> 00:07:17,930
Dann garantieren wir Ihnen auch, dass die Daten ausschließlich in Deutschland verarbeitet werden. Da gibt es mehrere Varianten zusammenzuarbeiten. Wir haben unsere Server grundsätzlich Berner Anbieter namens Hetzner. Das heißt, wenn Sie mit unserer Cloud zusammenarbeiten, wird das ausschließlich auf diesem Server verarbeitet. Oder wir können sogar unser gesamtes System bei Ihnen auf dem Server installieren. Haben wir bei sehr großen Kunden schon auch gemacht. Einfach damit die Daten ihr System einfach gar nicht mehr verlassen. Dann natürlich, dass die Daten von unseren Kunden ausschließlich ihnen zur Verfügung stellen. Also sowohl die Extrakte im Prinzip, die Sie mit unserer Query rausbekommen, als natürlich die Daten, die Sie bei uns hochladen.
Florian Polak: 00:07:18,170 –> 00:07:58,670
Wir nutzen Ihre Daten nicht zu Trainingszwecken, außer natürlich, das ist gewünscht. Also wir können auch im Prinzip speziell für Ihren Fall dann natürlich auch ein eigenes Datentraining durchführen. Und last but not least, wenn Sie sehr, sehr große Datenmengen haben Sie haben bei uns keine Begrenzung an hochgeladenen Daten, das heißt, Sie können da wirklich rein jagen, was auch immer Sie da drinnen haben, weil und kriegen trotzdem ein sehr performantes Ergebnis, werde ich nachher kurz noch mal ein bisschen was dazu sagen, dass Sie auch bei großen Datenmengen tatsächlich relevante Ergebnisse sehr präzise rausbekommen. Gut, dann steige ich auch schon ein mit Problemen grundsätzlich bei Studie Auswertung von Studien mittels KI.
Florian Polak: 00:07:59,570 –> 00:08:39,169
Das Hauptthema ist das Thema Halluzination. Also im Prinzip wirklich, dass die KI Ergebnisse bringt, die eigentlich nicht relevant sind. Um auf die Frage, die sie gestellt haben wir Es gibt da verschiedene Mechanismen, die man entgegenwirken kann. Ich werde nachher kurz ein bisschen was dazu sagen, was das eigentlich ist oder was üblicherweise die. Die Gründe dafür sind dann ein sehr, sehr wichtiges Ergebnis. Ich weiß nicht. Ich nehme mal an, dass viele von Ihnen schon mittlerweile mit Start up oder ähnlichen KI Systemen gearbeitet haben. Grundsätzlich gibt es geht es ja auch teilweise jetzt schon ganz gut. Allerdings sind im Regelfall gerade bei großen Datenmengen die Ergebnisse relativ ungenau oder unpräzise und eher oberflächlich.
Florian Polak: 00:08:39,590 –> 00:09:19,370
Dafür gibt es ganz gute Gründe, zu denen ich auch gleich noch ein bisschen was sagen werde. 121 anderes Thema natürlich. Je nachdem, in welchem Anbieter sie arbeiten, werden Daten teilweise zu Trainingszwecken weiterverwendet, weil die Systeme erst im Prinzip im Aufbau sind oder sich ständig weiterentwickeln. Oder die Daten werden natürlich in Anbieter an die USA weiter übermittelt. Als Beispiel wäre da zB IT zu nennen und beispielsweise das ist natürlich ein großes Risiko, weil ihre sensiblen internen Daten dann eventuell in zukünftigen Modellen im Prinzip als Antwort auch rauskommen können, was natürlich nicht in ihrem Interesse ist. Und sie haben sich auch schon ein bisschen was darüber gehört über das Thema Tokens.
Florian Polak: 00:09:19,880 –> 00:10:22,610
Und grundsätzlich trugen sie es in der Art und Weise, wie an solche Komodelle im Regelfall abrechnen oder bzw. wie. Wie viele Informationen auf einmal verarbeitet werden können. Das Man kann sich unter einem Token ungefähr ein Wort vorstellen, Das heißt, wie viele Wörter können von der KI gelesen werden? Da gibt es Limitierungen. Grundsätzlich. Zwar werden diese Kontextwindows im Prinzip also die Art, die Anzahl an Wörtern, die sie einspielen können, zwar immer größer, trotzdem haben sie da immer noch eine Limitierung, die natürlich nicht gewünscht ist. Wenn man große Datenmengen also von einer ganzen Studie beispielsweise auswerten möchte. Und eines der wichtigsten Themen für uns ist im Prinzip Nicht nur die tatsächlichen Ergebnisse der KI sollten angezeigt werden, sondern auch tatsächlich die Originalzitate, also die Originaltext stellen aus den Studien, die nämlich auch relevant sind, um vor allem den Kontext besser zu verstehen, aber auch natürlich, um zu überprüfen, ob die Antwort der KI tatsächlich richtig ist oder ob es sich beispielsweise um eine Halluzination handelt.
Florian Polak: 00:10:22,820 –> 00:11:03,950
Das sind so die wichtigsten Themen eigentlich in diesem Bereich. Ich werde mal kurz erzählen, grundsätzlich, was für Technologie sich hinter TTP versteckt. Es handelt sich um etwas, das nennt sich Large Language Model. Es sind verschiedene Arten von Modellen, aber im Prinzip basiert eigentlich alles auf dieselbe Art und Weise. Ist im Prinzip ein Modell, das gemacht wurde, um Sätze zu vervollständigen, basierend auf Wahrscheinlichkeit, das heißt, basierend auf dem Kontext, den Sie als Frage stellen, und dem Kontext, den Sie beispielsweise als Studie in das System hineinspielen. Versucht die ZBD beispielsweise die, den Satz zu vervollständigen, so dass er möglichst akkurat ist.
Florian Polak: 00:11:06,110 –> 00:11:45,920
Man muss sich darunter vorstellen Diese ganzen großen Land Language Modellen wurden mit Milliarden und Milliarden von Daten im Prinzip gefüttert. Das heißt, sie haben Milliarden von Daten im Prinzip gesehen und Sätze gelesen und können dann aufgrund dieser Trainingsdaten im Prinzip Sätze vervollständigen. Das ist im Wesentlichen eigentlich, was die Technologie hinter JPC ist. Das bedeutet natürlich, dass diese Systeme manchmal ist die wahrscheinlichste Antwort die korrekte. Das muss aber nicht immer der Fall sein. Das kann auch passieren, dass das System irgendwo abbiegt, die Frage zum Beispiel falsch versteht oder auch den falschen Kontext hat, um die Antwort im Prinzip zu generieren.
Florian Polak: 00:11:46,100 –> 00:12:25,880
Und dann passiert etwas, was im Umgangssprachlichen mittlerweile Halluzinieren genannt wird. Das ist im Prinzip ein Sammelbegriff für viele verschiedene Probleme. Das ist im Regelfall der Hauptgrund ist darauf, dass die KI im Prinzip. Auf die falschen Daten zurückgreift und dann im Prinzip die falschen Informationen liefert, um die Frage zu beantworten. Aus Nutzerperspektive ist es natürlich Sie stellen eine Frage, wollen eine Antwort haben und das System liefert Ihnen eine völlig falsche Antwort, was objektiv falsch ist und im Prinzip dann unter Halluzinieren zusammengefasst wird. Letztes Thema, was auch sehr, sehr wichtig ist, Wo ich gerade vorhin erwähnt habe, diese Kontextwindows oder auf deutsches Kontextfenster.
Florian Polak: 00:12:25,910 –> 00:13:01,730
Das ist im Prinzip schon ein bisschen ein Markttrends von den großen, laut Language Modellen sehr großen KIs, die im Moment am Markt sind. Die Idee der ganzen Sache ist, möglichst viele Daten auf einmal in das System einspielen zu können, um dadurch einen besseren Kontext für die KI zu generieren. Dadurch, dass das somit die Fragen dann besser beantwortet werden können. Die größten Modelle, die aktuell am Markt sind, sind meines Wissens nach das von Google, wo fast 1 Million solcher Tokens im Prinzip auch gleichzeitig verarbeitet werden können. Sie können da ein ganzes Buch reinschmeißen und dann im Prinzip Fragen an dieses Buch stellen.
Florian Polak: 00:13:02,720 –> 00:13:36,980
Problem bei der ganzen Sache ist, dass erstens mal ist es ein recht ineffiziente System, weil jedes Mal, wenn Sie eine Frage stellen an diese Daten, muss das gesamte Buch neu analysiert werden, was eine sehr ineffiziente Art und Weise ist. Und zwar sind diese Modelle zwar mittlerweile immer billiger, aber sie haben immer noch das Problem, dass wenn sie sehr, sehr viele Fragen stellen wollen, was bei Studien häufig vorkommt, dass ihnen dann ziemlich viel Kosten entstehen können. Und das zweite ist, was wahrscheinlich noch viel wichtiger ist Nur weil Sie einen größeren Kontext haben, heißt das nicht, dass die Antwort besser wird.
Florian Polak: 00:13:37,640 –> 00:14:14,030
Unbedingt. Zwar wird das System einen größeren Kontext haben und wird besser verstehen, um was es hier eigentlich geht. Also was hier die Studie zum Beispiel ist, heißt aber nicht, dass es eine präzise Antwort geben wird. Da komme ich ja schon zum nächsten Punkt. Warum sind denn solche KI Antworten manchmal so oberflächlich? Hintergrund der ganzen Sache ist, dass diese KIs im Prinzip darauf trainiert sind, möglichst natürlich richtige Aussagen zu treffen und keine falschen Antworten zu liefern. Eine Methode, um so was zu machen, ist im Prinzip den Kontext, die Kontextfenster zu erhöhen und mehr Daten reinzuspielen, um mehr Informationen zu zu liefern.
Florian Polak: 00:14:14,540 –> 00:14:58,820
Das Problem mit der ganzen Sache ist, dass das System darauf trainiert ist, bloß keine Fehler zu machen und bloß keine falschen Antworten zu liefern. Und aus diesem Grund im Prinzip versucht, eine Antwort zu generieren, die möglichst allgemeingültig ist und ja nicht falsch ist und in dem Kontext eben richtig ist oder und und und lieber eine oberflächliche Antwort gibt, als dass es einen tatsächlichen Fehler macht. Und das ist im Prinzip auch der Grund, warum dann im Prinzip seine Antwort relativ oberflächlich und ja allgemeingültig, aber vielleicht nicht besonders hilfreich für eine Studie ist. Was zur Folge hat das, dass diese Systeme tatsächlich in manchen Studien einfach gar nicht richtig oder gut eingesetzt werden können.
Florian Polak: 00:14:59,900 –> 00:15:41,120
Das ist so das Hauptthema. Das heißt, man muss sich ein bisschen bei diesen gängigen KI Systemen überlegen. Geht man das Risiko ein, dass das Ding halluziniert oder möchte man lieber oberflächliche Antworten haben? Und das ist im Prinzip das Hauptthema, was gerade am Markt mit diesen KI Modellen das problematisch ist. Wir gehen ein bisschen in eine andere Richtung und wir haben. Grundsätzlich werde ich ein bisschen erzählen, wie wir die Infrastruktur hinten aufgebaut haben, um genau diese beiden Probleme nicht zu haben, sondern um wirklich sehr, sehr tief reinzugehen, sehr, sehr präzise Antworten zu generieren, auch bei sehr großen Datenmengen, ohne das Problem zu haben, dass wir auf der anderen Seite Halluzinierung Stimmen haben oder die Antworten einfach sehr generisch sind.
Florian Polak: 00:15:42,980 –> 00:16:30,260
Im Prinzip Was macht unsere KI eigentlich oder was macht das System dahinter? Wir haben einen Text hier im Beispiel ist es jetzt ein Transkript. Wir haben zum Beispiel einen Audiofall von Ihnen bekommen. Das wurde von uns transkribiert. Das heißt, wir haben ein Wortprotokoll des Interviews und jetzt geht unser System über diesen Text und bricht diesen Text auf in Themenblöcke. Das heißt, es nennt sich im Fachsprache nennt sich das Ganze Junking, Das heißt im Prinzip wir wir. Ein System geht über diesen Text und schaut sich an, wo beginnt ein Thema und wo hört es wieder auf und generiert dann ebensolche solche Inhaltsblöcke und bricht diesen langen Text, der ja auch bei einer Stunde Interview mehrere 20 30 Seiten lang sein kann, in kleine Blöcke auf, die dann wiederum abgelegt werden in einem eigenen Datenbanksystem.
Florian Polak: 00:16:30,260 –> 00:17:12,619
Das Datenbanksystem nennt sich Vektor Datenbank. Es ist im Prinzip ein Datenbanksystem, das gut geeignet ist, Inhalte miteinander zu vergleichen. Das heißt, man kann sich vorstellen, ein ganzes Interview wird aufgebrochen. Man hat dann beispielsweise 1000 solche Themenblöcke und diese Themenblöcke werden dann auf dieser Datenbank als Graphen, also in einen mathematischen Wert umgewandelt und auf diese Datenbank abgelegt. Wenn Sie jetzt eine Frage haben und beispielsweise wissen wollen okay, fanden die Teilnehmer. Immer den Kunden Service gut und das System wird diese Frage wiederum analysieren. Um was geht es hier in Aufbrechen in so einen Themenblock und diesen Themenblock ebenfalls auf diese Vektordatenbank ablegen.
Florian Polak: 00:17:13,700 –> 00:17:56,060
Jetzt hat man diese zwei Themenblöcke und das System ist ganz gut geeignet zu vergleichen, Wie nah sind die aneinander dran? Das heißt, das System sucht dann auf Ihre Antwort alle relevanten Stellen in diesem Transkript raus, die geeignet sind, um Ihre Frage zu beantworten. Und diese Textblöcke werden dann genommen, werden dann eben so eine KI weitergegeben, die nicht mehr das ganze Transkript liest, sondern ausschließlich diese Themenblöcke. Daraus dann im Prinzip eine Antwort generiert und ihre Frage beantwortet hat zwei Vorteile Nummer eins Wir, die grundsätzlich. Die Antwort ist sehr, sehr präzise, weil sie im Prinzip wirklich ausschließlich den Text liest, der relevant ist, um Ihre Frage zu beantworten.
Florian Polak: 00:17:56,720 –> 00:18:30,620
Und das Zweite ist Wir können eine Rückverfolgbarkeit von Informationen garantieren. Das heißt, wir zeigen Ihnen grundsätzlich nicht nur einfach nur die Antwort der KI an, sondern wir zeigen Ihnen auch alle Textblöcke an, die relevant waren, um diese Frage zu beantworten. Und auf einmal können wir eine Rückverfolgbarkeit garantieren, was zur Folge hat, dass wir nicht nur Ihre Frage beantworten können, sondern sie das Ganze auch einfach überprüfen können. Das ist im Prinzip unser System und wir haben jetzt verschiedene Anwendungsfelder, wo wir das im Prinzip einsetzen. Erstes Thema ist beispielsweise bei diesem Kodieren von offenen Antworten in quantitativen Studien.
Florian Polak: 00:18:30,740 –> 00:19:15,890
Also beispielsweise Sie haben 1000 Antworten von Teilnehmern einer Onlinestudie, die im Prinzip einfach Informationen geben, was Sie zu dem Kundenservice gesagt haben. Jeder dieser Aussagen wird im Prinzip jetzt wiederum selbes Prinzip aufgebrochen in diese Themenblöcke. Manchmal ist so eine Antwort ja durchaus sehr, sehr lange. Dann sind es dann mehrere Themenblöcke, die werden wiederum abgelegt und die Codes, die im Prinzip genutzt werden, um das Ganze zu verdichten, werden ebenfalls als Themenblöcke abgelegt. Und dann wird eigentlich nur noch miteinander verglichen Was passt gut, welche Codes passen gut zu dieser Aussage? Und so kann man diese Ergebnisse relativ schnell verdichten, ohne die Gefahr zu gehen, dass die Ergebnisse falsch zugeordnet werden.
Florian Polak: 00:19:17,390 –> 00:19:58,070
Natürlich kann man da relativ lange Studien einfügen. Also die größten, die wir jetzt mittlerweile haben, waren glaube ich 20.000 Textnennungen, die dann im Prinzip dort nur System durch gejagt wurden. Verschiedene Datenformate unterstützen wir. Klassisch sind natürlich Excel oder SS, da dann das ganze Thema wird einfach einmal durch codiert. Das dauert im Durchschnitt für so 1000 Nennungen zirka zwei Minuten. Man kann sich die Ergebnisse natürlich wieder anschauen, kann eventuell auch nachbessern, wenn man das möchte, also einen anderen Code zum Beispiel verwenden. Oder man kann sogar dem System sagen, hier sind alle Nennungen, finden wir einen guten Code bei, nachdem ich das Ganze verdichten kann drüben.
Florian Polak: 00:19:58,520 –> 00:20:45,780
Und das Ganze im Prinzip dann durch Codieren lassen. Und die Formate können dann wieder als Excel oder SSDatei wieder exportiert werden. Das nächste Thema ist eher in der qualitativen Forschung. Hmmm. In der qualitativen Forschung geht es mir darum, Interviews oder Gruppendiskussionen tatsächlich zuerst einmal in Text zu transkribieren. Da haben wir Verschiedenes, verschiedenste Spracherkennungsalgorithmen für die verschiedenen Sprachen. Im Regelfall können wir alle romanischen Sprachen gut abdecken. Wir können vor allem im Deutschen, wo unser Fokus liegt, auch die verschiedenen Dialekte und Akzente auch ganz gut im Prinzip kennen. Je nach Aufnahmebedingungen schaffen wir da im Durchschnitt circa 95 % Genauigkeit.
Florian Polak: 00:20:45,780 –> 00:21:34,050
Das entspricht einer geschulten Transkriptionspersonen, die im Prinzip daneben sitzt und jedes Wort mitprotokolliert. Dann haben Sie mal den. Das Wortprotokoll, also im Prinzip das Transkript des Interviews oder der Gruppendiskussion. Und wenn es sich um eine Gruppendiskussion handelt, kann zum Beispiel dann automatisch auch das Gespräch nach Sprechern aufgebrochen werden. Das heißt, wenn Sie beispielsweise fünf Leute zu einem Thema befragen, wird dann schon aufgebrochen nach Sprecher, ein Sprecher, zwei Sprecher, drei Sprecher vier und fünf natürlich. Und sie können nachher dann wiederum, weil das System das Ganze dann aufbricht, wiederum sich aussuchen. Okay, möchte ich eine Analyse über alle Teilnehmer machen oder möchte ich wirklich tatsächlich einfach für jeden Sprecher relevante Informationen rausziehen?
Florian Polak: 00:21:35,250 –> 00:22:16,650
Und das System gibt Ihnen dann im Prinzip die Antworten auf Ihre Fragen. Das kann zum Beispiel der Leitfaden sein, den Sie hinterlegen oder auch Ihre Research fragen, um spezifisch nach bestimmten Informationen zu suchen. Das Spannende der Sache ist Sie können ein Interview hochladen und das analysieren. Oder Sie können ein ganzes Studio hochladen, um viele verschiedene Informationen aus den beispielsweise zehn Interviews rauszuziehen, um dann gemeinschaftlich einfach sich ein Bild zu machen über diese verschiedenen qualitativen Studien, die Sie da durchgeführt haben. Und der letzte Punkt ist wirklich tatsächlich, dass wir unser neuestes Modul eigentlich, dass wir tatsächlich große Mengen an Daten im Prinzip anbinden können.
Florian Polak: 00:22:16,650 –> 00:23:03,240
Ein klassisches Beispiel wären zum Beispiel Social Media Kanäle, die Sie per API Schnittstelle zum Beispiel anschließen können, um dagegen dann Fragen zu stellen. Sprich da werden Datenpunkte im Prinzip von Ihnen in unser System eingespielt, maschinenlesbar. Der Text muss das Ganze sein und dann können Sie tatsächlich Ihre Fragen gegen diese Datensätze stellen. Das können Exceldateien sein, das können Textdateien sein, über eine API zum Beispiel. Das können aber auch Transkripte von Interviews natürlich sein, um dann wirklich eine gesamt einheitliche Auswertung über diesen diese ganze Studie zu machen. Wunderbar geeignet natürlich für andere Communities, wo es grundsätzlich relativ viele Daten gibt, wo auch über mehrere Tage oder Wochen hinaus gewisse Informationen gesammelt werden von Usern, um dann wirklich so eine Auswertung tatsächlich zu machen.
Florian Polak: 00:23:03,870 –> 00:23:55,080
Das System zeigt ihnen dann immer die Antwort an, aber auch die Referenzen wirklich von den jeweiligen Textblöcken wiederum woher die Informationen eigentlich kommen, sodass sie dann leicht eine Möglichkeit haben, das Ganze zu überprüfen. Genau. Als Epischnittstelle können Sie das natürlich anschließen. Ähm, grundsätzlich wie funktioniert unser System? Gibt grundsätzlich mal zwei Möglichkeiten, wieder zusammenzuarbeiten. Wir können das Ganze bei Ihnen auf dem Server installieren. Das wäre dann so eine On Premise Installation. Das heißt, dann wird das Ganze wirklich auf Ihren Server betrieben. Keine Daten verlassen Ihr Unternehmensnetzwerk. Der einzige Nachteil, den Sie da haben, abgesehen davon, dass es ein bisschen umständlich ist, ist, dass Sie da relativ starke Server brauchen, inklusive solche Grafikkarten, also GPUs genannt, die geeignet sind, im Prinzip, um diese Systeme sehr performant laufen zu lassen.
Florian Polak: 00:23:55,470 –> 00:24:39,750
Oder sie entschließen sich, das Ganze auch mit uns zusammenzuarbeiten in der Cloud. Da garantieren wir Ihnen wie gesagt, dass die Daten ausschließlich in Deutschland verarbeitet werden. Das ist dann im Prinzip auf unserem Server, der in Nürnberg steht. Serveranbieter ist ein deutsches Unternehmen namens Hetzner und wo im Prinzip dann die Daten analysieren zu lassen. Ähm, grundsätzlich natürlich sind diese Systeme hinreichend gesichert, sprich wir verarbeiten ihre Daten auch wirklich nur so, wie sie das Ganze von uns wünschen. Gibt da verschiedene Möglichkeiten, wie wir zusammenarbeiten können. Man kann auch eigene Datentrainings für sie machen, wenn sie das wünschen. Und es gibt natürlich auch die Möglichkeit in anderen EU Ländern beispielsweise einen Cloudserver aufzubauen, was wir grundsätzlich auch schon in der Vergangenheit gemacht haben.
Florian Polak: 00:24:41,390 –> 00:25:18,530
Zu den Preisen gibt es zwei verschiedene Art und Weise, mit uns zusammenzuarbeiten. Das eine Thema wäre wirklich so einer on demand. Das heißt wirklich, Sie haben ein Projekt, Sie kommen auf uns zu und sagen, wir wollen jetzt dieses Projekt mit ihnen durchführen. Wir machen ein Angebot und rechnen dann nach der Studie im Prinzip ab. Da rechnen wir grundsätzlich immer nach Datensätzen ab, also im Prinzip, wenn es sich um qualitative Interviews handelt. Das rechnen wir meistens über Audiostunden ab. Wenn es sich um Excel Dateien handelt, die abgerechnet werden müssen, haben Sie, zahlen Sie einen Cent pro Betrag für eine Pro Excel Zelle, also pro Nennung des Befragten und rechnen das Ganze völlig flexibel ab.
Florian Polak: 00:25:18,530 –> 00:25:54,140
Keine Bindung, oder? Wir haben auch natürlich das Corporate Offer. Das machen wir bei größeren Kunden mit uns, dass sie einen jährlichen Fixpreis haben, dann haben sie keine Mengeneinschränkung, können das Ganze mit uns machen nach Lust und Laune und können auch bauen das Ganze für sie im Prinzip dadrauf. Das kann natürlich auch alles kombiniert werden. Das heißt, es gibt natürlich auch die Möglichkeit, dass man zum Beispiel eine qualitative Studie durchführt, die Ergebnisse dann verdichtet. Im Prinzip. Beispielsweise im Quantenmodul, dass man dann wirklich das Ganze auf wirkliche Wortnennungen verdichtet und das Ganze kodiert, um dann eine sehr, sehr gute Auswertung zu kriegen.
Florian Polak: 00:25:54,140 –> 00:26:31,070
Und um sich einen Report im Prinzip schnell herzurichten. Das wäre auch schon alles von meinem Webinar. Jetzt würde ich ganz kurz auf die Fragen eingehen, die Sie grundsätzlich hier im Chat gestellt haben. So gibt es die Möglichkeit, Audiodateien zu testen zu lassen. Starke Dialekt aus Österreich zum Beispiel. Ja, grundsätzlich. Sie können das bei uns auch immer alles testen. Das heißt da einfach uns gerne unverbindlich einfach schreiben. Wir bieten natürlich immer die Möglichkeit an, das Ganze auszuprobieren, sei das jetzt eben bei Audiodateien mit Akzenten zum Beispiel, aber auch natürlich bei Excel Studien, dass Sie das mal ausprobieren können und sich von der Qualität überzeugen.
Florian Polak: 00:26:31,880 –> 00:27:11,870
Bei den Akzenten Grundsätzlich gilt je in Österreich vor allem je weiter östlich, desto leichter, je weiter westlich, desto schwieriger. Schweizer Akzente und Dialekte sind tatsächlich ein bisschen problematisch, weil es keine keine einheitliche Art gibt, wie man Schweizerdeutsch schreibt. Deswegen gibt es auch wenig Möglichkeiten, da leicht einen Spracherkennungsalgorithmus aufzubauen. Wir haben aber schon die verschiedensten Projekte auch in Österreich gemacht. Sprich einfach kontaktieren und einfach ausprobieren, würde ich vorschlagen. Dann die nächste Frage war dann auch noch Können auch Transkripte von Face to Face Gruppendiskussionen mit Zuordnung der sprechenden Person gemacht werden oder nur von anderen Gruppen? Face to face geht auch.
Florian Polak: 00:27:11,870 –> 00:27:53,330
Wir brauchen grundsätzlich eine Aufnahme in einer Art oder oder der anderen. Also beispielsweise, wenn Sie wirklich eine Face to Face Studie haben und das Ganze aufnehmen, können Sie nachher die Audiodateien nehmen, hochspielen und das Ganze dann im Prinzip transkribieren lassen. Wir wir machen das nicht über die verschiedenen Kanäle, also beispielsweise bei einem Online Meetings über Teams gibt es ja die verschiedenen Sprecherkanäle und im Regelfall hat man bei der Transkription dann so eine Aufteilung nach den verschiedenen Kanälen. Wir machen das Ganze über eine eigene Sprechererkennung, das heißt, wir haben da einen eigenen Algorithmus drinnen, der die Unterschiede in den Stimmlagen erkennt und das Gespräch danach im Prinzip auf aufbricht, quasi.
Florian Polak: 00:27:54,260 –> 00:28:28,400
Bedeutet aber natürlich auch, dass das wir nicht wissen, dass ich zum Beispiel der Florian Pollack bin, sondern wir wissen eigentlich dann auch nur okay. Es gab fünf Sprecher in diesem Gespräch und folgender Sprechereinsatz folgende Sachen gesagt natürlich, wenn man nachher die Informationen wieder braucht, um eine Analyse zu fahren, beispielsweise, dass man die Analyse machen möchte, über was die weiblichen Teilnehmer der Studie gesagt haben, dann kann man diese Referenzen wieder einfügen. Das müsste dann manuell im Nachhinein gemacht werden von Ihnen, geht aber recht schnell, um dann nachher im Prinzip in der Auswertung auf der Ebene auch noch machen zu können.
Florian Polak: 00:28:29,840 –> 00:29:11,360
Haben Sie auch Familien mit Schweizer deutschen Dialekten? Ja, haben wir. Schweizerdeutsche Dialekte sind leider etwas schwierig, muss ich noch dazu sagen. Wir haben mittlerweile ein neues Modell, das glaub ich nächste Woche rauskommt, das tatsächlich für Schweizerdeutsch Ergebnisse bringt, die, sagen wir mal deutlich besser sind als das, was sie bisher am Markt kennen. Wir müssten dann allerdings auch ausprobieren, wie die wie die Qualität wirklich ist, weil das eben ein sehr, sehr neues Modell ist. Grundsätzlich ist das ein bisschen schwieriger natürlich als österreichisch oder oder deutsch Deutsch mit den verschiedenen Dialekten und Akzenten dort. Und dann kann man von Ihnen anonymisierte, pseudonymisierte Beispiele für eine Textauswertung erhalten, um ein Gefühl für die Ergebnistypen zu bekommen.
Florian Polak: 00:29:11,360 –> 00:29:52,440
Ja, können Sie, wenn Sie grundsätzlich mit uns machen. Meistens dann so eine Demo. Da haben wir auch eine Demostudie drinnen, wo Sie das Ganze sich einmal anschauen können und durchaus dann im Prinzip das Ganze auch verwenden können, um selber sich zu überprüfen, ob das System passt oder nicht. Dann kann die ja vorher die Webseite oder Dokumente crawlen und Spezialbegriffe Spezialabkürzungen zu identifizieren. Wir haben viele Fachbegriffe, die auch von Kunden verwendet werden. Grundsätzlich. Das Thema Spezialbegriffe ist immer wieder relevant. Für qualitative Studien ist es insbesondere dann relevant, weil die Spracherkennung basiert nämlich auch auf dem üblichen Sprachgebrauch.
Florian Polak: 00:29:52,860 –> 00:30:42,570
Wenn es dann Spezialbegriffe gibt, Eigennamen, Firmennamen beispielsweise. Sowas kann im Regelfall sehr, sehr einfach im Prinzip hochgeladen werden, in dem sie eigentlich ein Level hochladen, Ob wir es von der Webseite crawlen. Grundsätzlich einen Service. Wir haben theoretisch Crawler mit so was zu machen. Effizienter wäre es wahrscheinlich, wenn wir einfach im Prinzip sie uns die Webseite sagen. Wir schauen uns das Ganze für Sie an, erstellen wir eine Excelliste an diesen Fachbegriffen und laden die einmal hoch. Das dauert im Regelfall zwei drei Minuten, ist recht schnell gemacht und dann werden die Begriffe auch richtig erkannt. Üblicherweise, wenn es sich um Webbegriffe handelt, die auf Webseiten sind, macht es in der Textauswertung gar nicht mal so groß eine Rolle, weil die KI Systeme im Regelfall mit sehr, sehr großen Datenmengen gefüttert wurden, sodass auch Spezialbegriffe dann auch richtig erkannt werden.
Florian Polak: 00:30:42,570 –> 00:31:26,060
Also ein Kontext passt dann im Regelfall ganz gut. Insofern sollte das damit auch eher kein Problem sein. Und welche Sprachen können Sie abbilden? Alle europäischen und auch nichteuropäischen Sprachen. Grundsätzlich also was auf jeden Fall sehr, sehr gut funktioniert, sind die romanischen Sprachen, also Deutsch, Englisch, Französisch, Spanisch, Italienisch. Wir hatten dann aber auch Niederländisch, Dänisch, die auch gut funktioniert haben. Im Englischen natürlich die verschiedenen Sprachgruppen, die wir haben. Also wir hatten tatsächlich auch eine Studie, die mit singapurianischen Akzenten waren, wo ich in der Spracherkennung, also ich persönlich hätte weniger verstanden als unsere KI da tatsächlich. Also da gibt es auch die verschiedensten Möglichkeiten.
Florian Polak: 00:31:26,070 –> 00:31:56,130
Wir haben aber auch die Möglichkeit, wenn es, sagen wir mal, eine sehr exotische Sprache ist, die nicht sehr häufig vorkommt, hier noch mit anderen Anbietern zusammenzuarbeiten. Dann müssten wir uns aber im konkreten Fall anschauen, was sie da brauchen. Und auch da müssen wir uns genau noch mal erkundigen, wie das Ganze funktioniert, dass wir auch garantieren können, dass die Daten ausschließlich auf unserem Server verarbeitet werden, weil das dann halt eine Spracherkennung ist, die wir nicht anbieten, da gerne einfach auf uns zutreten. Wir können dann im Spezialfall gerne noch mal drüber reden, wenn wir schon beim Thema Sprache sind.
Florian Polak: 00:31:56,160 –> 00:32:42,570
Ein wichtiger Punkt geht auch Beispiel insbesondere bei qualitativen Studien. Sie können auch im Prinzip, wenn Sie einen Leitfaden beispielsweise auf Deutsch haben und die Studien mehrsprachig sind, also beispielsweise auf Englisch und auf Deutsch, dann können Sie das Ganze transkribieren lassen, auf Englisch und jeweils auf Deutsch und dann aber den Leitfaden nehmen, um den auch auf die englischen Transkripte gegen die zu stellen, sodass die Antworten aus dem Kontext, aus dem englischen Transkript raus extrahiert werden, um dann im Prinzip aber auf Deutsch übersetzt werden. Das funktioniert. Es ist genaugenommen kein Übersetzungsprogramm, sondern es ist, dass die KI versteht den Kontext der anderen Sprache, weil die Trainingsdaten in sowohl auf Englisch als auch auf Deutsch zur Verfügung waren.
Florian Polak: 00:32:42,840 –> 00:33:17,060
Das funktioniert erstaunlich gut. Das heißt, Sie können auch mehrsprachige Studien mit uns durchführen, ohne weitere Probleme. So, dann die nächste Frage Können mehrere Sprachen gleichzeitig verboten werden? Ja, das war kurz die Frage, die ich gerade beantwortet haben. Also zum Beispiel für Studien in Belgien. Ja, das geht grundsätzlich. Also wenn Sie eine französischsprachige Studie haben und das andere wäre Flämisch, zum Beispiel, sollte das kein Problem sein, müssten wir das einmal transkribieren in die jeweilige Sprache. Und wenn Sie dann Ihren Leitfaden aus auf beispielsweise Deutsch haben, werden die Antworten im Prinzip genutzt, um dann ein Ergebnis zu produzieren.
Florian Polak: 00:33:17,070 –> 00:34:08,850
Also Ihre Antwort zu der Frage zu beantworten. Wenn Sie denn die Zitate haben wollen, sind die dann logischerweise aber in der Originalsprache. Und die letzte Frage Können bei quantitativen Studien demografische Daten mit offenen Ländern verknüpft werden dann die Texte danach analysiert, also zum Beispiel bei Männern ist es so und bei Frauen ist es so, Ja, das geht also grundsätzlich. Das wäre dann am ehesten unser letztes Modul, von dem ich gesprochen habe, dieses hier, dass Sie dann eine ganze Excel hochladen, wo dann die ganzen relevanten Datenpunkte drinnen sind und sie dann dagegen einfach die Fragen stellen. Also da können Sie dann auch eine Auswertung machen nach Geschlechtern, nach Informationen, die grundsätzlich in diesen Exceldateien drin sind, um relevante Ergebnisse zu machen, kann natürlich auch kombiniert werden mit den anderen Modulen, die wir haben, um dann so ein Excel zu produzieren, gegen das Sie dann im Prinzip Ihre Research Fragen stellen können.
Florian Polak: 00:34:10,320 –> 00:34:46,139
Okay, wunderbar. Dann waren das, glaube ich, alle Fragen. Hatte es noch eine Frage? Können Sie die Preise der Pakete bitte noch mal wiederholen? Wir haben. Jetzt kommt ein bisschen darauf an, in welcher Kombination Sie das Ganze machen wollen. Bei den Preisen gilt es grundsätzlich zwei Varianten zusammenzuarbeiten Entweder Abrechnung nach Projekten. Das heißt, Sie haben beispielsweise zehn Interviews, die Sie mit uns transkribieren und dann auswerten wollen und wir machen. Ich gebe Ihnen einen Preis, nachdem Sie das Ganze auswerten können und sie zahlen dann nach Durchführung des Projektes. Oder die Variante ist, dass Sie einen Pauschalpreis mit uns machen.
Florian Polak: 00:34:46,139 –> 00:35:17,370
Da kommt es wie gesagt darauf an, welche Funktionen Sie gerne haben wollen. Und dann machen wir einen Pauschalpreis pro Jahr. Und dann ist es uns auch egal, wie viele Studien Sie darüber laufen lassen. Kommt darauf an, in welchem Kontext Sie machen. Das Corporate aber macht im Regelfall dann Sinn, wenn Sie viele Datenmengen haben oder sehr, sehr viele Studien durchführen. Ansonsten würde ich Ihnen wahrscheinlich dazu raten, das Ganze auf Projektbasis Minus zu machen. Gut, dann vielen Dank, dass Sie heute ins Webinar gekommen sind. Wenn Sie grundsätzlich noch Fragen haben Sie können. Meine Emailadresse finden Sie hier unten.
Florian Polak: 00:35:17,820 –> 00:35:38,190
Sie können uns jederzeit natürlich auch schreiben. Grundsätzlich werden wir auch, glaube ich, eine Zusammenfassung von diesem Webinar auch nochmal zirkulieren. Die Zusammenfassung ist dann auch schnell generiert für unsere Studie. Dann haben Sie da auch schon mal einen Überblick, wie gut das System eigentlich erarbeitet und habe mich sehr gefreut, dass Sie heute gekommen sind. Und ich wünsche Ihnen noch einen schönen Nachmittag. Vielen Dank!
Ein umfassender Überblick über die Webinarthemen
Das Webinar bot den Teilnehmern eine systematische Darstellung der Rolle der KI in der Marktforschung und behandelte folgende Themen:
- Die Grundlagen von KI-Systemen und ihre Anwendung in der Marktforschung.
- Strategien zur Bewältigung gängiger KI-Integrationsherausforderungen, mit einem Fokus auf die speziellen Methoden von Tucan.ai.
- Ein detaillierter Einblick in die Produktpalette von Tucan.ai mit Fallstudien, die die Problemlösungsfähigkeiten in realen Szenarien demonstrieren.
- Die Bedeutung der Datensicherheit bei KI-Anwendungen und das Engagement für den Schutz der Kundendaten.
Zentrale Einsichten und Diskussionspunkte
Ein Höhepunkt des Webinars war Florian Polaks Erklärung von "KI-Halluzinationen". Er nutzte die Analogie zu einem Bibliothekar, um das Data Chunking und die Vektordatenbanken von Tucan.ai zu beschreiben, die dafür sorgen, dass die KI wie ein erfahrener Bibliothekar effizient durch riesige Mengen an Informationen sortieren kann, um genau die Erkenntnisse zu finden, die benötigt werden, ohne sich ablenken zu lassen.
Praktische Tipps für Marktforschungsexperten
Das Webinar enthielt umsetzbare Ratschläge, unter anderem:
- Implementierung der Anti-Halluzination-Mechanismen zur Validierung von KI-generierten Erkenntnissen, wobei Polak betont: "Genauigkeit ist der Eckpfeiler unserer KI-Lösungen."
- Anwendung von KI zur schnellen Codierung offener Umfrageantworten, wodurch stundenlange manuelle Arbeit in eine Aufgabe verwandelt wird, die nur wenige Minuten dauert.
- Nutzung der mehrsprachigen Fähigkeiten von Tucan.ai zur Analyse verschiedener Datensätze, um umfassende und integrative Forschungsstudien zu ermöglichen.
Der KI-Vorteil
Indem sie die spezifischen Herausforderungen von Marktforschern mit modernsten KI-Lösungen angehen, können Marktforscher nicht nur ihren Forschungsprozess rationalisieren, sondern auch zuverlässigere und umsetzbare Erkenntnisse gewinnen. Ob für Nischenstudien oder groß angelegte Projekte, KI-Tools können auf die besonderen Anforderungen jeder Forschungsinitiative zugeschnitten werden.
Steigern Sie Ihre Produktivität um das Zehnfache!
Case Study: Analyse qualitativer Studien in 1 Tag statt 2 Wochen
Laden Sie die Case Study kostenlos herunter!
Entdecken Sie, wie durch KI von Tucan.ai die Verarbeitung qualitativer Studien in einem Marktforschungsunternehmen optimiert und die Effizienz sowie Genauigkeit gesteigert wurde.






Die wichtigsten Ergebnisse
Diese Case Study demonstriert den effektiven Einsatz von KI zur Verbesserung der Marktforschung, mit signifikanten Fortschritten in der Analysezeit und Datenqualität:
- Effiziente Analyse: Verkürzung der Auswertungszeit von qualitativen Studien von 14 Arbeitstagen auf 10 Stunden verbessert die Agilität in der Marktforschung.
- Verbesserte Genauigkeit: Durch eine Genauigkeitsrate von 97% trägt die innovative Chunking-Technologie von Tucan.ai zu verlässlichen und präzisen Ergebnissen bei.
- Optimierte Abläufe: Anpassungen des Systems an spezifische Anforderungen des Unternehmens führen zu gesteigerter Effizienz, reduzieren manuelle Arbeit und senken dadurch operative Kosten.
Diese Fortschritte unterstützen nicht nur eine schnellere Entscheidungsfindung, sondern tragen auch zu einer gesteigerten Wettbewerbsfähigkeit des Unternehmens "K" bei.
Laden Sie die Case Study kostenlos herunter!
Wir beraten Sie zu Ihrem Use-Case!
Case Study: KI-automatisierte Vertragsanalyse mit 98% Genauigkeit
Laden Sie die Case Study kostenlos herunter!
Entdecken Sie, wie eine Anwaltskanzlei durch die Implementierung des KI-Systems von Tucan.ai ihre Vertragsanalyse-Prozesse transformiert hat:





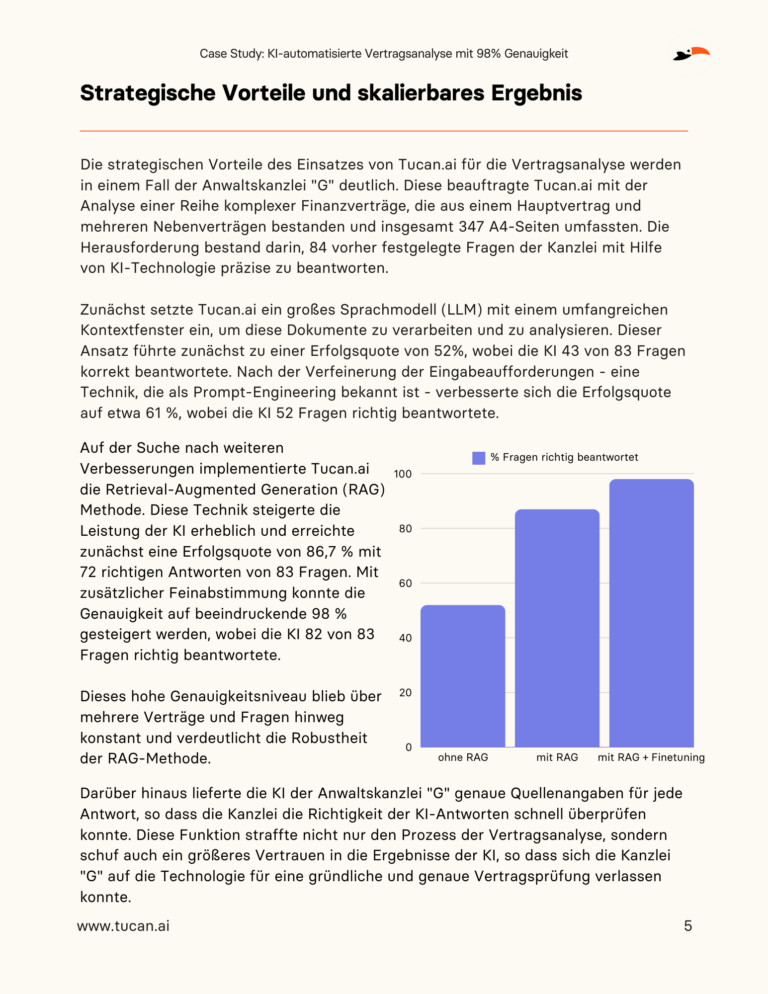

Die wichtigsten Ergebnisse
Diese Case Study zeigt, wie der Einsatz von KI-Technologie nicht nur die Effizienz in der Vertragsanalyse erheblich steigert, sondern auch die juristische Genauigkeit verbessert und die Bearbeitungszeiten verkürzt:
- Dramatische Beschleunigung: Reduzierung der Analysezeit für komplexe Verträge auf nur eine Stunde.
- Hohe Genauigkeit: Durch die innovative Chunking-Technik erreichte die KI eine Analysegenauigkeit von 98%, was das Vertrauen in die juristischen Prozesse stärkt.
- Strategische Verbesserungen: Skalierbare Ergebnisse durch die Implementierung der RAG-Methode, mit Konsistenz über mehrere Verträge und Ergebnissen mit genauen Quellenangaben.
Diese Innovationen haben nicht nur die Vertragsanalyse vereinfacht, sondern auch die strategische Leistungsfähigkeit der Kanzlei gestärkt.
Laden Sie die Case Study kostenlos herunter!
Wir beraten Sie zu Ihrem Use-Case!

KI für Vertragsanalysen und Recherchearbeiten: was Sie beachten müssen.
Laden Sie das Whitepaper kostenlos herunter!
Künstlichen Intelligenz (KI) hat in verschiedenen Branchen eine neue Ära der Effizienz und Effektivität eingeläutet, wobei der Rechtsbereich keine Ausnahme bildet. Da die Komplexität von Rechtsfällen mit dem exponentiellen Wachstum von Daten zunimmt, erscheint KI als Hoffnungsträger für die Rationalisierung von Abläufen, die Senkung von Kosten und die Verbesserung der Genauigkeit und Qualität der juristischen Arbeit. Die Integration von KI in rechtliche Zusammenhänge ist jedoch nicht frei von Herausforderungen. In unserem Whitepaper "KI für Vertragsanalysen und Recherchearbeiten: was Sie beachten müssen." gehen wir genau auf diese Fragen ein und bieten Juristen einen leicht verständlichen Leitfaden zu den neuesten KI-Technologien, die für juristische Anwendungen geeignet sind.











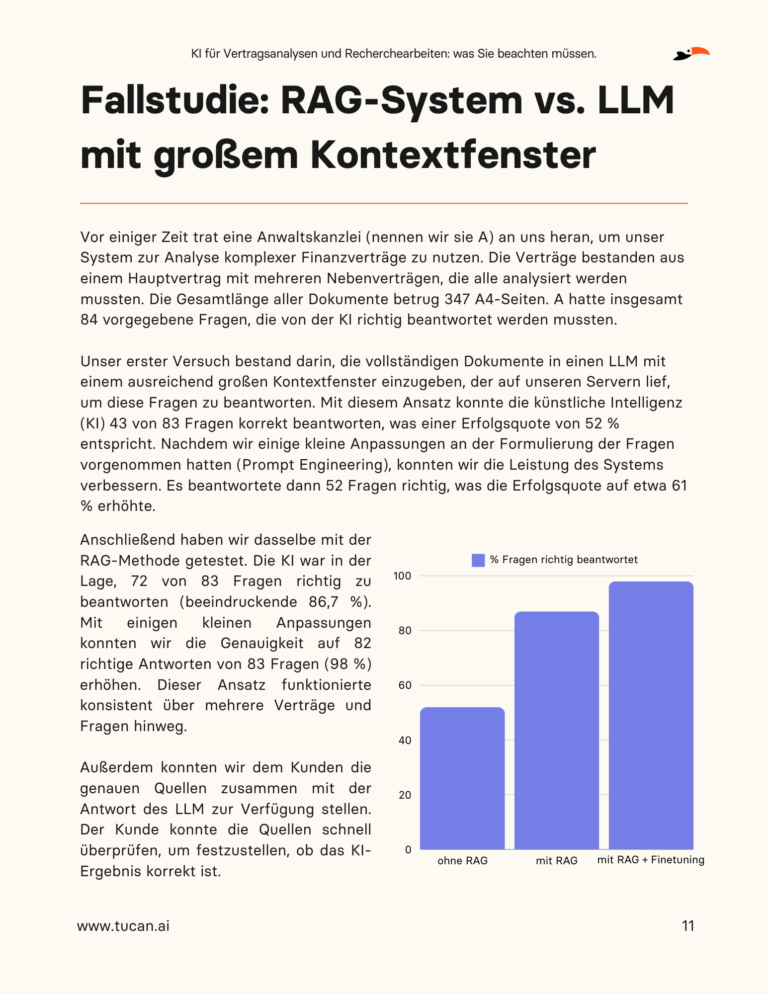





Zentrale Herausforderungen bei der Einführung von KI in der Rechtsbranche
In der Rechtsbranche ist der Einsatz von KI, insbesondere von Large Language Models (LLMs), zwar transformativ, steht aber vor erheblichen Herausforderungen, die eine nahtlose Integration erschweren. Das Problem der "Halluzinationen", bei denen KI überzeugende, aber ungenaue Antworten liefert, hat zu ernsthaften Konsequenzen geführt, wie z. B. Geldstrafen, die Anwälten auferlegt wurden, weil sie ChatGPT für fiktive juristische Recherchen eingesetzt haben. Außerdem steht die Undurchsichtigkeit der KI-Entscheidungsfindung, die als "Black Box" bezeichnet wird, im Widerspruch zu den Forderungen des Rechtssektors nach Transparenz und Zuverlässigkeit. Die Schwierigkeiten der KI, komplexe menschliche Anfragen zu verstehen, und die Abhängigkeit von Prompt-Engineering unterstreichen die Grenzen ihres kontextuellen Verständnisses. Die strengen Anforderungen der Branche an den Datenschutz und die Sicherheit erschweren die Nutzung von Cloud-basierten KI-Lösungen zusätzlich. Schließlich wirft der sich entwickelnde Charakter von KI-Modellen Fragen der Zuverlässigkeit und Konsistenz auf, da die Antworten auf identische Anfragen im Laufe der Zeit variieren können. Diese Herausforderungen unterstreichen die Notwendigkeit eines sorgfältigen und fundierten Ansatzes für die Nutzung von KI in der Rechtspraxis.
Laden Sie das Whitepaper kostenlos herunter!
Innovationen und Lösungen
In dem Bestreben, die Anwendung von KI im juristischen Bereich voranzutreiben, sind bemerkenswerte Innovationen und Lösungen entstanden. Die Einführung von Retrieval Augmented Generation (RAG)-Systemen stellt einen entscheidenden Fortschritt dar, da sie eine Methode bieten, um präzise und genaue Antworten zu liefern, indem sie umfangreiche Texte in überschaubare Segmente zerlegen. Dies erhöht nicht nur die Genauigkeit der Ergebnisse, sondern trägt auch Bedenken hinsichtlich des Datenschutzes Rechnung, indem es den Betrieb von KI auf privaten Servern erleichtert. Darüber hinaus hat die Entwicklung neuartiger Chunking-Techniken, bei denen Texte auf der Grundlage des Kontexts und nicht anhand fester Parameter segmentiert werden, die Fähigkeit der KI zur Analyse von Rechtsdokumenten erheblich verbessert. Zudem stellt die Automatisierung des Prompt-Engineering eine bahnbrechende Lösung für die Herausforderungen der Eingabegenauigkeit dar. Durch die Entwicklung von Systemen, die reguläre juristische Anfragen automatisch in KI-verständliche Formate übersetzen, kann die ursprüngliche Absicht der Fragen deutlich besser gewahrt und die Präzision der Ergebnisse erhöht werden. Zusammen versprechen diese Innovationen eine effektivere und sicherere Integration von KI in der Rechtsbranche und eröffnen neue Wege für ihre Anwendung.
Um sich in der komplexen Landschaft der KI in der Rechtsbranche zurechtzufinden, ist es von entscheidender Bedeutung, ihre Vorteile und Fallstricke zu verstehen. Unser Whitepaper ist ein Guide für Juristen, die KI durchdacht und erfolgreich in ihre Praxis integrieren wollen.
Laden Sie das Whitepaper kostenlos herunter!
Wir beraten Sie zu Ihrem Use-Case!
Strategien zur Analyse riesiger Textmengen mit KI: der Einsatz von Chunking und Vektordatenbanken
Im Zeitalter der digitalen Transformation öffnen Large Language Models (LLMs) neue Wege für die Analyse riesiger Textmengen, die in Datenbanken gespeichert sind. Diese fortschrittlichen KI-Systeme halten das Versprechen, tiefe Einblicke und Wettbewerbsvorteile aus der Datenfülle zu gewinnen. Jedoch stoßen sie durch die sogenannte Token-Limitierung, eine technische Begrenzung der verarbeitbaren Datenmenge, an ihre Grenzen. Dies wird besonders beim Versuch, Millionen von Textdokumenten tiefgehend zu analysieren oder neue Erkenntnisse zu gewinnen, zur herausfordernden Hürde:
Angenommen, ein Unternehmen möchte 1.000.000 Textdokumente analysieren. Bei Verzicht auf spezielle Methoden steht es vor großen Problemen: Durch Token-Limitierung kann ein LLM nur Teile der Dokumente pro Durchlauf analysieren, was zu Informationsverlust führt. Ohne Zerlegung in handhabbare Einheiten und ohne eine semantisch intelligente Datenbank entsteht ein erheblicher Kontextverlust. Dokumente müssen isoliert betrachtet werden, was die Gewinnung tiefergehender Einsichten erschwert. Zudem ist die Analyse extrem zeitaufwendig und ressourcenintensiv, da jedes Dokument einzeln in vollem Umfang bearbeitet werden muss.
Chunking & Vektordaten: problemlos 1.000.000+ Dokumente analysieren
Eine wirkungsvolle Methode, diese Limitierung zu umgehen, ist die Kombination aus dem smarten Chunking und dem Einsatz von Vektordatenbanken. Durch das Zerlegen komplexer Texte in kleinere, für LLMs handhabbare Abschnitte (Chunking), wird die Analyse großer Datenmengen ohne die Beschränkungen durch Token-Limits möglich. Zusätzlich erleichtern Vektordatenbanken durch ihre Fähigkeit, semantische Vektorrepräsentationen schnell und effizient zu verarbeiten und abzufragen, den Zugriff auf und die Analyse von relevanten Informationen erheblich. Diese Kombination steigert die Verarbeitungskapazität und Präzision von LLMs signifikant und eröffnet die Möglichkeit, die volle Leistungsfähigkeit der Technologie zu nutzen, um aus der Datenflut wertvolle Einsichten zu ziehen.
KI Wissensmanagement Onepager herunterladen
Bei der Analyse großer Datenmengen, wie etwa 1.000.000 Textdokumenten, verändert sich so der Analyseprozess deutlich:
- Effiziente Datenbearbeitung: Durch das Aufteilen der Dokumente in kleinere Einheiten (Chunking) werden sie für LLMs leichter verarbeitbar, da Token-Limitierungen umgangen werden.
- Erweiterte Kontextualisierung: Vektordatenbanken ermöglichen durch das schnelle Zuordnen semantisch ähnlicher Textteile eine tiefere Kontextanalyse. Dies verbessert das Verständnis und die Einordnung von Informationen erheblich.
- Zeiteffizienz und Skalierbarkeit: Die Dokumente werden in kleinere Teile zerlegt und Informationen mittels Vektordatenbanken effizient abgerufen. Dies beschleunigt die Verarbeitung signifikant, optimiert die Analyse und spart Ressourcen.

Praxisbeispiele
Beispiel für die Rechtsabteilung eines Private Equity Fonds
Ein Private Equity Fonds verwendet LLMs, um die Compliance seiner umfangreichen und länderübergreifenden Vertragsdatenbank zu überprüfen. Die Herausforderung liegt in der enormen Datenmenge und der Notwendigkeit, spezifische regulatorische Anforderungen in verschiedenen Ländern effizient zu identifizieren.

- Chunking-Anwendung: Vor der Analyse werden alle Dokumente in thematisch relevante Abschnitte aufgeteilt. Dies ermöglicht dem LLM, seine Analysefähigkeiten gezielt auf relevante Textsegmente anzuwenden und die Genauigkeit der Ergebnisse erheblich zu verbessern.
- Vektordatenbank-Integration: Relevante Abschnitte und gesetzliche Bestimmungen werden in der Vektordatenbank gespeichert. Das LLM nutzt diese, uml die relevantesten Gesetzestexte und Compliance-Anforderungen auf die spezifischen, rechtlichen Fragen abzurufen.
KI Wissensmanagement Onepager herunterladen
Die Ergebnisse sind eine deutlich effizientere und tiefgründigere Analyse der Compliance, wobei regulatorische Risiken minimiert werden und die Anpassung an internationale Gesetze erleichtert wird.
Beispiel für die Marktforschungsabteilung eines großen Unternehmens
Eine Marktforschungsabteilung setzt LLMs ein, um aus Millionen von Verbraucherfeedbacks, Marktberichten und Social-Media-Beiträgen Trends und Muster abzuleiten.
- Chunking-Anwendung: Das Aufteilen der Daten in kleinere, thematisch fokussierte Segmente ermöglicht es dem LLM, präziser und in einem kontrollierten Kontext zu arbeiten, wodurch die Genauigkeit der Trendanalyse verbessert wird.
- Vektordatenbank-Integration: Durch die Speicherung von thematischen Vektoren aus den analysierten Textchunks in der Vektordatenbank kann das LLM relevante Themen und Trends über einen umfassenden und vielfältigen Datensatz hinweg konsistent und effizient aufspüren.
KI Wissensmanagement Onepager herunterladen

Diese Strategie ermöglicht es dem Unternehmen, schnell auf sich ändernde Marktbedingungen zu reagieren und maßgeschneiderte Marketingstrategien zu entwickeln, die auf tiefgreifenden, datengetriebenen Einblicken basieren.
In beiden Fällen erweisen sich Chunking und Vektordatenbanken als unverzichtbare Werkzeuge, um die Stärken von LLMs voll auszuschöpfen. Durch diese Techniken können Unternehmen die Leistungsfähigkeit von KI in der Textanalyse steigern, wodurch sie tiefere Einsichten gewinnen und präzisere Entscheidungen treffen können.
Informationsfluten effizient bewältigen mit KI
In einer Zeit der Informationsüberflutung ist es für Unternehmen entscheidender denn je, ihre Daten nicht nur zu verwalten, sondern sie intelligent zu nutzen. Tucan.ai bietet mit seiner in Deutschland entwickelten Chunking-Technologie und der Integration in Vektordatenbanken eine wegweisende Lösung, die Präzision, Effizienz und Datenschutz in den Vordergrund stellt. Ob es darum geht, komplexe Verträge zu analysieren, Markttrends zu identifizieren oder datenschutzkonforme Entscheidungen zu treffen, Tucan.ai ermöglicht es Unternehmen, ihre Datenverarbeitung zu revolutionieren und fundierte Entscheidungen auf Basis verifizierbarer und präziser Daten zu treffen. Entdecken Sie die transformative Kraft von Tucan.ai und stellen Sie sicher, dass Ihr Unternehmen an der Spitze der datengestützten Entscheidungsfindung steht.
Managen Sie Ihr Wissen präzise, skalierbar und DS-GVO-konform!
Beyond ChatGPT: Zukunftsweisende Lösungen für präzises, skalierbares und sicheres Wissensmanagement mit KI
In der heutigen datengetriebenen Welt stehen Unternehmen vor der gewaltigen Aufgabe, aus ihren enormen Datenmengen wertvolle Erkenntnisse zu gewinnen. Der Einsatz von KI öffnet dabei komplett neue Wege. Doch wenn es um die präzise Analyse vieler Dokumente geht, stoßen gängige Systeme wie ChatGPT an ihre Grenzen. Hier kommt Tucan.ai ins Spiel, ein Vorreiter in der Nutzung des innovativen Chunking-Ansatzes für präzise und effiziente Datenanalyse. Dieser Blogbeitrag führt Sie in die Herausforderungen ein, mit denen Unternehmen bei der Nutzung traditioneller KI-Systeme konfrontiert sind, und stellt Tucan.ai vor, der die Landschaft des KI-gestützten Wissensmanagements verändert.
KI Wissensmanagement Onepager herunterladen
Inhaltsverzeichnis
Probleme mit gängigen KI-Systemen wie ChatGPT
Angesichts des wachsenden Bedarfs von Unternehmen, ihre umfangreichen Datenmengen für intelligentes Wissensmanagement zu nutzen, hat die Anbindung an gängige KI-Systeme wie ChatGPT vielversprechende Perspektiven eröffnet. Allerdings birgt dieser Ansatz eine Reihe signifikanter Herausforderungen, die bei der Planung und Implementierung solcher Systeme nicht außer Acht gelassen werden dürfen.
Risiko von KI-Halluzinationen
Beim Anschluss der Unternehmensdaten und Datenbanken an gängige KI-Systeme, wie ChatGPT, besteht die Gefahr sogenannter KI-Halluzinationen. Das bedeutet, die künstliche Intelligenz erzeugt Antworten, die nicht auf den realen, unternehmensspezifischen Daten basieren. Diese fehlerhaften oder irreführenden Informationen können beträchtliche Auswirkungen haben, vor allem in Szenarien, wo präzise und verlässliche Daten für Entscheidungsprozesse kritisch sind. Unternehmen stehen somit vor der Herausforderung, den Output solcher Systeme kontinuierlich zu überwachen und zu validieren, um Fehlinformationen zu vermeiden.
Fehlende Quellenreferenzen
Ein weiterer Mangel bei der Nutzung gängiger KI-Systeme für das Wissensmanagement in Unternehmen ist das Fehlen von Quellenreferenzen in den generierten Antworten. Diese Limitation bedeutet, dass die Informationen, die vom System bereitgestellt werden, schwierig zurückzuverfolgen und auf ihre Richtigkeit hin zu überprüfen sind. In Umgebungen, in denen es auf Genauigkeit und Verlässlichkeit der Daten ankommt, erschwert dies die Nutzung solcher Systeme für fundierte geschäftliche Entscheidungen erheblich.
Limitierung anhand von Tokens
Gängige KI-Systeme unterliegen Limitierungen in der Anzahl von Tokens, die sie verarbeiten können, was bei der Anbindung an Unternehmensdatenbanken für Wissensmanagementzwecke zu Problemen führt. Die Token-Limitierung hindert die KI daran, umfangreiche Unternehmensdaten in einem Durchgang zu analysieren und effizient zu verarbeiten. Für Unternehmen, die große Volumen an Textdaten analysieren müssen, kann diese Beschränkung die Usability und Effizienz des KI-Systems erheblich mindern.
Datenschutz im Sinne der DSGVO
Die Integration von gängigen KI-Systemen in die Dateninfrastruktur eines Unternehmens bringt Datenschutzbedenken, speziell gemäß der DSGVO, mit sich. Viele dieser Systeme trainieren auf umfangreichen Datenbeständen, die potenziell persönliche Informationen beinhalten können, ohne klare Zustimmung der betreffenden Personen. Für Unternehmen bedeutet dies ein juristisches Risiko, sollte ihre KI-Anwendung nicht den strengen Datenschutzanforderungen entsprechen. Dies erfordert zusätzliche Ressourcen für die Gewährleistung der DSGVO-Konformität, einschließlich der transparenten Darlegung, wie und welche Daten verarbeitet werden.
KI Wissensmanagement Onepager herunterladen
Tucan.ai: Ein innovativer Lösungsansatz, Made In Germany
Tucan.ai repräsentiert mit seiner in Deutschland entwickelten Technologie einen bahnbrechenden Ansatz im Bereich des KI-gestützten Wissensmanagements. Durch die Verwendung von fortschrittlichen Algorithmen für das Chunking transformiert Tucan.ai die Art und Weise, wie Unternehmen auf ihre Daten zugreifen und sie analysieren. Dieser präzisionsorientierte Ansatz ermöglicht eine effiziente Segmentierung von Textdaten in thematisch relevante Abschnitte, die in Vektordatenbanken für eine transparente und verifizierbare Analyse integriert werden. Tucan.ai setzt neue Maßstäbe für die Datenanalyse, indem es Präzision, Effizienz und Datenschutz in den Mittelpunkt stellt.
Was ist Chunking?
Im Mittelpunkt des fortschrittlichen Wissensmanagements steht das Konzept des Chunkings, ein Ansatz, der zunehmend von Unternehmen in Betracht gezogen wird, um die Effizienz und Präzision der Datenanalyse mittels KI zu verbessern. Chunking bezeichnet das Verfahren, bei dem große Mengen an Textdaten oder Informationen in kleinere, thematisch relevante Einheiten, auch bekannt als „Chunks“, unterteilt werden. Diese Technik ermöglicht es, den Umfang und die Komplexität von Daten zu reduzieren, indem nur die relevantesten Abschnitte für die Analyse und Verarbeitung herangezogen werden.

Bedeutung für Unternehmen
Für Unternehmen kann der Einsatz von Chunking in KI-basierten Wissensmanagementsystemen mehrere bedeutende Vorteile haben. Zunächst ermöglicht es eine gezielte Analyse einzelner Datenblöcke, ohne dass der KI-Algorithmus von der Fülle irrelevanter Informationen überwältigt wird. Dies führt nicht nur zu präziseren und relevanteren Ergebnissen, sondern verbessert auch die Effizienz der Datenverarbeitung. Darüber hinaus können Unternehmen durch diesen Ansatz sicherstellen, dass ihre KI-Systeme sich auf die wirklich wichtigen Daten konzentrieren, was besonders bei der Verarbeitung sensibler oder vertraulicher Informationen von Bedeutung ist.
Erhöhte Effizienz in der Datenverarbeitung
Durch das Aufteilen von Daten in kleinere, thematisch kohärente Blöcke ermöglicht Chunking eine zielgerichtete Verarbeitung und Analyse. Dies verhindert, dass das System von der schieren Menge an Informationen überfordert wird, was besonders bei der Verarbeitung komplexer oder vielschichtiger Datenbestände von Bedeutung ist. Die Fähigkeit, spezifische Datenabschnitte exakt und schnell zu analysieren, führt zu einer deutlichen Steigerung der Effizienz im Wissensmanagement.
Verbesserte Genauigkeit und Relevanz von Insights
Eines der Kernprobleme großer Datensätze ist die Identifikation von relevanten Informationen. Durch das Prinzip des Chunkings können KI-Systeme genau die Datenblöcke analysieren, die für eine bestimmte Anfrage oder ein bestimmtes Problem relevant sind. Dies führt zu präziseren Antworten und Insights, da irrelevante Informationen systematisch ausgefiltert werden. Für Unternehmen bedeutet das, dass sie sich auf die generierten Insights verlassen können, um informierte Entscheidungen zu treffen.
Vereinfachung komplexer Datenanalysen
Die Fähigkeit, große und komplexe Datensätze in überschaubare Einheiten zu unterteilen, vereinfacht die Datenanalyse erheblich. Diese Strukturierung macht es möglich, tiefergehende Analysen durchzuführen, ohne in der Datenfülle verloren zu gehen. Für Felder wie Marktforschung, Kundenanalytik oder Vertragsanalyse, wo detaillierte und spezifizierte Insights erforderlich sind, bietet Chunking einen klaren Vorteil.
Verbesserter Datenschutz und Compliance
Das Prinzip des Chunkings ermöglicht es auch, die Verarbeitung und Analyse von Daten zu kontrollieren und zu beschränken. Besonders im Hinblick auf den Datenschutz und die Einhaltung von Vorschriften wie der DSGVO kann dies entscheidend sein. Unternehmen können spezifischer bestimmen, welche Daten analysiert werden sollen, was das Risiko der Verarbeitung sensibler Informationen ohne entsprechende Genehmigung minimiert.
![]()
KI Wissensmanagement Onepager herunterladen
Chunks in Vektordatenbanken: Ermöglichung genauer Quellenreferenzen
Die Integration von Thematischen Blöcken oder "Chunks" in Vektordatenbanken bildet einen innovativen Ansatz, der die Funktionsweise der Datenspeicherung und -abfrage revolutioniert, insbesondere im Kontext von KI-gestütztem Wissensmanagement. Doch warum ist diese Integration so wirkungsvoll und wie trägt sie zu genauen Quellenreferenzen bei?
Bedeutung von Vektordatenbanken
Vektordatenbanken speichern Informationen als Vektoren, ein Format, das sich besonders gut für die Analyse und Verarbeitung durch Algorithmen des maschinellen Lernens eignet. Diese Art von Datenbanken ist optimal für die Handhabung hochdimensionaler Daten geeignet und ermöglicht komplexe Abfragen und Analysen mit hoher Geschwindigkeit – ein wesentlicher Vorteil bei der Suche nach spezifischen Informationen innerhalb riesiger Datensätze.
Verbindung von Chunks und Vektordatenbanken
Durch die Speicherung von Chunks als individuelle Vektoren in Vektordatenbanken können KI-Systeme schnell und effizient auf genau die Datenabschnitte zugreifen, die für eine Anfrage relevant sind. Dies führt zu einer präzisen und schnellen Zuordnung von Quellenreferenzen. Jeder Chunk kann mit spezifischen Metadaten versehen werden, einschließlich Quellenangaben, was eine nachvollziehbare und verifizierbare Datenanalyse ermöglicht.
Vorteile für Unternehmen
1. Erhöhte Transparenz:
Durch die explizite Zuweisung von Quellen zu den analysierten Datensegmenten wird die Herkunft der Informationen transparent, was für Compliance und Vertrauensbildung entscheidend ist.
2. Ermöglichung genauer Quellenreferenzen:
Dies erleichtert die Validierung und Überprüfung der durch die KI generierten Insights, was besonders in Bereichen wichtig ist, wo die Genauigkeit der Daten von kritischer Bedeutung ist.
![]()
3. Verbesserung der Datenqualität und der Analyseergebnisse:
Die klare Zuordnung von Daten zu den entsprechenden Quellen minimiert Verwirrungen und Fehler, die durch fehlerhafte oder irreführende Informationen entstehen könnten.
4. Effizientes Datenmanagement:
Die Fähigkeit, gezielt auf relevante Informationen zuzugreifen, ohne gesamte Datenbestände durchforsten zu müssen, spart Zeit und Ressourcen.
KI Wissensmanagement Onepager herunterladen
Anwendungsbeispiele
Die Vielfalt und Breite potenzieller Anwendungen von Chunking in der Unternehmenslandschaft ist enorm. Nachfolgend finden Sie zwei ausgewählte Beispiele, die lediglich die Oberfläche dieses facettenreichen Ansatzes kratzen und die transformative Kraft verdeutlichen, die das Chunking für spezifische professionelle Anforderungen entfalten kann.
Vertragsanalysen für Anwälte
Ein herausragendes Anwendungsbeispiel für Chunking im Unternehmensumfeld findet sich in der juristischen Praxis. Anwälte stehen oft vor der Herausforderung, umfangreiche Vertragsdokumente zu analysieren, um spezifische Klauseln, Bedingungen und Verpflichtungen zu identifizieren und zu verstehen. Durch die Anwendung von Chunking können Vertragsdokumente in kleinere Einheiten unterteilt werden, die jeweils spezifische Aspekte des Vertrags, wie Haftungsbestimmungen, Kündigungsrechte oder Datenschutzklauseln abbilden. Dies ermöglicht es Anwälten, schnell und effizient auf relevante Abschnitte zuzugreifen und umfassende Vertragsanalysen mit einer bisher unerreichten Präzision durchzuführen.
Analyse umfangreicher Datensätze für Marktforscher
Für Marktforscher, die mit der Herausforderung konfrontiert sind, detaillierte Einblicke aus riesigen Mengen von Marktdaten zu gewinnen, bietet Chunking eine effektive Lösung. Durch die Unterteilung der Daten in thematisch relevante Chunks kann die KI gezielt nach Trends, Mustern und Konsumentenverhalten in verschiedenen Segmenten des Marktes suchen. Beispielsweise können Datenströme aus sozialen Medien, Kundenfeedbacks und Kaufhistorien in separate Chunks unterteilt werden, um spezifische Fragestellungen bezüglich Produktpräferenzen oder Käuferdemografien zu adressieren. Diese gezielte Analysestrategie ermöglicht es Marktforschern, präzisere Vorhersagen zu treffen und fundierte Entscheidungen zu unterstützen.
Informationsfluten effizient bewältigen mit KI
In einer Zeit der Informationsüberflutung ist es für Unternehmen entscheidender denn je, ihre Daten nicht nur zu verwalten, sondern sie intelligent zu nutzen. Tucan.ai bietet mit seiner in Deutschland entwickelten Chunking-Technologie und der Integration in Vektordatenbanken eine wegweisende Lösung, die Präzision, Effizienz und Datenschutz in den Vordergrund stellt. Ob es darum geht, komplexe Verträge zu analysieren, Markttrends zu identifizieren oder datenschutzkonforme Entscheidungen zu treffen, Tucan.ai ermöglicht es Unternehmen, ihre Datenverarbeitung zu revolutionieren und fundierte Entscheidungen auf Basis verifizierbarer und präziser Daten zu treffen. Entdecken Sie die transformative Kraft von Tucan.ai und stellen Sie sicher, dass Ihr Unternehmen an der Spitze der datengestützten Entscheidungsfindung steht.
Managen Sie Ihr Wissen präzise, skalierbar und DS-GVO-konform!
KI als Forschungsassistentin: Automatisierte Auswertung von Online-Community-Daten
In der Welt der digitalen Marktforschung sind Online-Communities Goldminen für wertvolle Verbraucherdaten. Sie bieten direktes Feedback und eröffnen Einblicke in Präferenzen und Verhaltensmuster der Zielgruppen. Doch die Auswertung dieser umfangreichen und vielfältigen Daten stellt viele Unternehmen vor Herausforderungen. Hier setzt Tucan.ai an und revolutioniert den Prozess der Datenauswertung – ein Fortschritt, der von Florian Polak im marktforschung.de Webinar eindrucksvoll präsentiert wurde. In diesem Beitrag erläutern wir die Kernpunkte dieser Innovation und zeigen auf, wie Tucan.ai völlig neue Wege in der automatisierten Datenanalyse beschreitet.
"Wir wissen, wie entscheidend die Transparenz und Zuverlässigkeit der von unserer KI Bereitgestellten Ergebnisse ist."
Interview Marktforschung.de mit Florian Polak
Geschäftsführer, Tucan.ai GmbH
Edit Content
Edit Content
Zusammenfassung des Webinars “KI als Forschungsassistentin: Automatisierte Auswertung von Onlinecommunitydaten”
Begrüßung und Einführung
Zu Beginn des Webinars begrüßte Sabrina Gehrmann die Zuschauer und stellte Florian Polak vor, den Mitbegründer und Geschäftsführer von Tucan.ai der zuvor als Produktmanager bei Careship gearbeitet hat. Sie wies darauf hin, dass Fragen während des Webinars über einen speziellen Button gestellt werden können und dass Florian Polak diese im Anschluss beantworten wird.
Vorstellung des Themas
Florian Polak führte in das Thema des Webinars ein, indem er die Bedeutung der KI in der Marktforschung, insbesondere bei der Auswertung von Online Communities, erläuterte. Er betonte, wie Forschungsfragen effizient mit großen Datenmengen in kurzer Zeit ausgewertet werden können und gab einen Überblick über die Funktionen und Vorteile der KI-Technologie in diesem Bereich.
Technischer Exkurs und Präsentation des Systems
Polak präsentierte das von Tucan.ai entwickelte System, das in der Lage ist, aus Texten, Audiodaten und Videos relevante Informationen zu extrahieren und zu verarbeiten. Er ging auf die technischen Aspekte des Systems ein, einschließlich der Verarbeitung und Auswertung von Daten, und erklärte, wie das System mit Herausforderungen wie Halluzinationen von KI und Datenschutz umgeht. Er stellte auch dar, wie das System die Zusammenarbeit mit KI-Technologien optimiert, ohne dass zusätzliche Mitarbeiter benötigt werden.
Anwendungsbereiche und Kundenreferenzen
Polak teilte einige Anwendungsbereiche und Kundenreferenzen mit, um zu zeigen, wie das System bereits erfolgreich eingesetzt wird. Er erwähnte namhafte Kunden wie die Bundeswehr, Telefonica, Porsche, Mercedes und Axel Springer, die das System für verschiedene Zwecke nutzen.
Fragen und Antworten
Im letzten Teil des Webinars beantwortete Florian Polak Fragen der Zuschauer zu verschiedenen Themen, darunter die Anwendung des Systems auf verschiedene Studientypen, Testmöglichkeiten vor der Beauftragung, Vergleiche zwischen Länderstudien, die Mindestmenge an Daten für eine zuverlässige Arbeit des Systems, die Erkennung von Dialekten und Schreibfehlern sowie die Kombination von quantitativen und qualitativen Daten.
Abschluss
Zum Abschluss bedankte sich Sabrina Gehrmann bei Florian Polak und den Zuschauern. Sie wies auf kommende Webinare hin und verabschiedete die Teilnehmer.
Edit Content
Sabrina Gehrmann: 00:00:07,070 –> 00:00:46,280
Es wartet wieder ein aufregendes Webinar auf uns. Deswegen würde ich sagen höchste Zeit, dass wir jetzt starten und damit. Hallo und herzlich willkommen, liebe Zuschauerinnen und Zuschauer zu diesem Webinar heute hier auf Marktforschung punkt.de. Mein Name ist Sabina Germann. Ich bin hier online Eventmanagerin im Haus und zum heutigen Webinar Ganz herzlich begrüßen darf ich Florian Polak. Er ist Mitbegründer und Geschäftsführer von Tucan.ai. Zuvor hat er bereits als Produktmanager bei Careship gearbeitet. Und nicht nur deswegen freuen wir uns sehr, ihn heute zu begrüßen. Deswegen auch an dich. Hallo Florian, schön, dass du da bist.
Florian Polak: 00:00:47,060 –> 00:00:47,930
Freut mich. Hallo!
Sabrina Gehrmann: 00:00:49,100 –> 00:01:31,460
Und für Sie noch der Hinweis Liebe Zuschauerinnen und Zuschauer, wenn Sie gleich in den nächsten 30 Minuten Fragen haben, dann stellen Sie die sehr gerne. Es gibt unten an Ihrem Bildschirmrand den Button F, A oder K und A. Dort einfach draufklicken, fragen, reinschreiben. Wir haben uns vereinbart, dass Florian alle Fragen dann im Anschluss beantworten wird. Deshalb gerne diese diese Möglichkeit nutzen. Aber jetzt freuen wir uns sehr auf die KI als Forschungsassistentin. Automatisierte Auswertung von Onlinecommunitydaten. Und damit gebe ich auch jetzt an dich ab. Florian, Du darfst gerne deinen Bildschirm teilen und ich wünsche Ihnen, liebe Zuschauerinnen und Zuschauer, jetzt ganz viel Spaß.
Florian Polak: 00:01:33,440 –> 00:02:14,420
Wunderbar. Ich hoffe, alle können den Bildschirm sehen. Sehr gut. Ja. Vielen Dank, dass ihr heute alle so zahlreich angekommen sind. Wie schon erwähnt, waren Pollock mein Name. Ich bin Geschäftsführer und Gründer von zugeneigt. Ich werde Ihnen heute ein paar Sachen zum Thema KI in der Marktforschung, vor allem im Hinblick auf Online Communities erzählen. Grundsätzlich Warum ist uns dieses Produkt oder wir bzw dieses Webinar ihre Zeit wert? Ich werde Ihnen ein bisschen zeigen, wie Forschungsfragen im Prinzip mit vielen, vielen Daten im Prinzip in wenigen Minuten eigentlich ausgewertet werden können. Ich gebe Ihnen ein paar Tipps und Tricks, wie diese KI funktioniert.
Florian Polak: 00:02:14,540 –> 00:02:53,660
Wir werden auch heute einen kurzen technischen Exkurs machen, was ich Ihnen zeige, was technisch unter der Haube eigentlich steht. Und ich werde Ihnen natürlich zeigen, wie Sie mit KI Technologien am besten zusammenarbeiten können, ohne dass das ohne zusätzliche Mitarbeiter im Prinzip deutlich deutlich mehr Studien auswerten können. Die Agenda für heute Ich werde mich kurz und knapp halten und viel Zeit auch noch für fragen zu lassen. Natürlich. Wir machen eine kurze Vorstellung über unser Unternehmen. Ich werde ein bisschen über das Probleme reden, die es grundsätzlich bei den anderen Communities geht. Ich werde auch von bestehenden KI Systemen, also z.B Tee usw was es dafür Schwierigkeiten immer wieder gibt.
Florian Polak: 00:02:54,170 –> 00:03:44,040
Dann werde ich eine kurze Übersicht über die Software geben. Kleine technischen Exkurs, dann Tiere reinschauen, reinschauen wie funktioniert und sich das System und noch ein paar Informationen zum Datenschutz und zu unseren Preisen sein. Dann starten wir ganz kurz zu uns. Ja, wir wurden 2019 gegründet. Es ist ein KI Unternehmen aus Berlin, mittlerweile mit mittlerweile 20 Mitarbeiter. Wir haben uns darauf fokussiert, aus Gesprächen, aber auch Texten relevante Informationen zu extrahieren und zu verarbeiten. Haben dabei auch einen Fokus auf sensible Informationen. Arbeiten auch in anderen Bereichen, aber vor allem natürlich auch in der Marktforschung und bieten da verschiedene Module an, unter anderem qualitative Kodierung, quantitative Kodierung, aber eben jetzt auch online Communities, die man tatsächlich auswerten kann, Produkte sich Inhalte vorstellen werde.
Florian Polak: 00:03:44,060 –> 00:04:25,790
Ist grundsätzlich. Wie können Sie Ihre Forschungsfragen an große Datenmengen stellen, um das System zu verwenden? Als Assistent quasi, denen die relevanten Informationen tatsächlich auswerten kann und Ihnen auch die Referenzen geben kann, zu den Originaltext stellen, sodass Sie sehr, sehr viele Textnennungen, aber auch verschiedene Formate wie Audio, Video oder auch Text tatsächlich mit diesem System auswerten können. Das System ist so aufgebaut, dass es immer zwei Dinge macht Es macht die Auswertung und es gibt Ihnen die Originaltext stellen. Und ich werde auch ein bisschen dazu sagen, wie wie es technisch funktioniert, damit Sie eine gewisse Grundvorstellung haben, wie das System aufgesetzt ist.
Florian Polak: 00:04:26,720 –> 00:05:10,020
Ein paar Referenzen. Wir arbeiten in Deutschland mit einigen großen Unternehmen schon zusammen. Der größte Kunde, den wir haben, ist die Bundeswehr. Aber auch Telefonica, Porsche, Mercedes und Axel Springer sind unsere Kunden. Ohne Communities grundsätzlich sehr wohl einsetzbar. Natürlich in der Praxis, weil es verschiedene Formate und verschiedene Auswertungstechniken kombiniert und natürlich die Möglichkeit besteht, sehr tief reinzugehen und gewisse Fokusgruppen im Prinzip auszuwerten. Der Teufel liegt allerdings im Detail. Es ist natürlich dann die Auswertung nachher zu führen, vor allem der qualitative Teil, aber auch diese Freitagsantworten zu quantifizieren und dann wirklich auszuwerten und ein gesamtheitlichen Überblick über die ganzen Studien durchzuführen.
Florian Polak: 00:05:10,020 –> 00:05:54,180
Das kann sehr, sehr zeitintensiv sein. Und da ist es besonders wichtig, wenn man vor allem eine Mischung hat aus qualitative Auswertung und quantitative Forschung, dass man wirklich diese Ergebnisse möglichst objektiv betrachtet und auswertet. Und das ist natürlich für eine Maschine etwas leichter als für Menschen, ist auch der Grund, warum wir glauben, dass wir tatsächlich als unterstützend hierfür für die Forscher glauben, dass das System, dass ich auch einen qualitativen Mehrwert bringt, grundsätzlich das Hauptthema natürlich. Man kann das natürlich alles manuell machen, wird ja auch seit einigen Jahrzehnten so gemacht. Grundsätzlich ist natürlich zwei Möglichkeiten Entweder man setzt fehlende Mitarbeiter ein oder heuert Externe dazu, um diese Analysen zu führen.
Florian Polak: 00:05:54,180 –> 00:06:31,920
Das ist teuer. Das kostet alles sehr, sehr viel Zeit. Und aus diesem Grunde ist im Prinzip der Punkt, dass wir uns auf diesen Bereich fokussieren, um eben die Auswertung maschinell unterstützt ein bisschen besser zu machen. Ähm, warum wir jetzt nicht einfach Systeme wie zB die verwenden? Es gibt ja mittlerweile auch mehrere KI Technologien, die rausgekommen sind seit zwei Jahren sehr prominent. Natürlich gibt ein paar Risiken, was das was problematisch finde in der Marktforschung tatsächlich zu dieser Auswertung von Studien ist. Eine Thema sind Halluzinationen. Das ist der Begriff im Prinzip, dass diese KI Algorithmen sehr, sehr gut geeignet sind, ihm Antworten zu liefern.
Florian Polak: 00:06:31,920 –> 00:07:12,810
Manchmal sind sie jedoch leider falsch und es gibt sehr, sehr wird sehr, sehr schwierig, wenn man dem System nicht vertrauen kann, wie man das am besten überprüfen kann. Das ist so eines der Hauptthemen hier in der Marktforschung. Das zweite Thema natürlich, wenn man so Unternehmen wie zB die im Prinzip für den Einsatz verwendet, man kriegt wahnsinnig gute Ergebnisse Tatsächlich. In manchen Bereichen jedoch gibt es immer das große Drama, dass diese Daten auch teilweise in die USA übermittelt werden. Insbesondere bei vertraulichen Studien ist das natürlich ein Thema und teilweise gibt es Anbieter, die das Ganze zu Trainingszwecken weiterverwenden, das heißt auch ihre Daten tatsächlich verwenden, um das System zu verbessern.
Florian Polak: 00:07:13,830 –> 00:07:54,600
Das hat ein riesen Nachteil. Natürlich, weil ihre vertraulichen Informationen theoretisch dann in diesen Trainingsdaten entstehen und in einer zukünftigen Variante von diesem Algorithmus möglicherweise als Antworten geliefert werden können. Hauptthema natürlich auch hier die Limitierung auf sogenannte Tokens. Das ist die Art und Weise, wie abgerechnet wird. Das heißt, man kann nur eine gewisse Anzahl an Wörter in diese Systeme reinspielen. Führt auch dazu, dass eben nicht alle die gesamte Studie ausgewertet werden kann, sondern dass aufgebrochen werden muss, was zu Inkonsistenzen für Assistenten führt, uns natürlich dazu führt, dass man deutlich deutlich länger braucht, um das System auswerten zu lassen.
Florian Polak: 00:07:55,290 –> 00:08:48,500
Aber das Hauptthema hier auch die Quellen fehlen. Also nochmal das Thema von der Überprüfung. Man muss einen einfachen Weg haben, diese Ergebnisse schnell überprüfen zu können. Originalzitate sind vor allem natürlich bei Studien sehr, sehr spannend. Und das ist genauso ein Thema, das essenziell für die Auswertung ist. Jetzt kommen wir zu unserem System. Grundsätzlich, Was ich Ihnen heute vorstelle, ist relativ forward. Sie haben die Möglichkeit, verschiedene Daten in das System einzuspielen. Das heißt, wir können Videos machen, wir können Audiodateien, die dann beide jeweils transkribiert werden in Text, aber auch Excel oder Elster Tan können hochgeladen werden in das System und dann können an diese Daten Fragen gestellt werden, die dann beantwortet werden von der KI und ausgewertet Tatsächlich und auch Referenzen geben zu den jeweiligen Originaltext stellen, um diese Überprüfung einfach zu machen.
Florian Polak: 00:08:49,700 –> 00:09:28,340
Ich will Ihnen gleich nachher noch mal erzählen, wie es technisch ein bisschen funktioniert. Wir grundsätzlich akzeptieren jede Art von maschinell lesbaren Text, aber auch eben Audio oder Videodateien, die dann von uns transkribiert werden in Text, damit danach ausgewertet werden kann. Verschiedene Formate, Excls, Dateien oder man kann das auch verbinden mit einer API Schnittstelle direkt mit Ihrem Programm, das Sie verwenden, quasi um diese Online Communities zu tun. Es gibt ein paar Garantien, die wir Ihnen geben können, und das eine Thema ist es, wenn der Antihalluzinations Mechanismus eingebaut haben, dass ihm genau dieses System nur aufgrund Ihrer Daten tatsächlich antwortet und nicht Sachen erfindet.
Florian Polak: 00:09:29,180 –> 00:10:06,590
Das zweite Thema ist, dass wir Ihnen garantieren, wenn Sie mit uns in der Cloud arbeiten, dass diese Daten ausschließlich in Deutschland auf unserem Server verarbeitet werden. Mittlerweile ist unsere Standort in Nürnberg und dort werden alle Daten im Prinzip verarbeitet. Zwei dritte Thema Es wir Mit jedem Kunden, den wir mit dem wir zusammenarbeiten, machen wir einen eigenen Cluster im Prinzip auf. Das bedeutet, dass Ihre Daten ausschließlich für Ihre Auswertung verwendet werden, nicht für Trainingsdaten, es sei denn, Sie geben uns die schriftliche Anweisung, dass wir das System manchmal nachtrainieren können für Ihren Use Case. Das ist allerdings nur, wenn Sie uns im Prinzip explizit anweisen.
Florian Polak: 00:10:07,070 –> 00:10:45,350
Und der letzte Punkt ist Es gibt keine Begrenzung an der Anzahl an hochgeladenen Datenmengen. Also Sie sind da völlig frei. Sie können da wirklich hochladen, was sie wollen, wie das System so aufgebaut ist, dass es trotzdem dieselbe Performance gibt. Egal ob das jetzt Terabyte von Daten sind oder tatsächlich nur ein einzelnes Transkript. Was macht unser System also grundsätzlich technisch? Ähm, wir machen im Prinzip zwei Dinge, um sicherzustellen, dass wir große Mengen an Text im Prinzip aufbrechen können. Hier ist ein Beispiel von einem Transkript. Grundsätzlich geht es auch mit einer Exceldatei. Also jede Art von Text wird so aufgebrochen.
Florian Polak: 00:10:45,950 –> 00:11:38,210
Das macht das System. Der erste Schritt ist, dass wir ein sogenanntes inhaltliches Junking machen. Chucking bedeutet, dass wir unseren Text anschauen und den aufbrechenden Themengebieten. Sprich das System versteht den Kontext eines Satzes und schaut sich an Was ist inhaltlich in diesem Satz gerade genannt? Es schaut sich dann auch nochmal an okay, welche anderen Punkte in diesem Transkript oder in dieser Exceldatei passen noch zu diesem Thema und fügt diese Sachen dann zusammen und macht sogenannte Chunks, also solche Themenblöcke, die dann genutzt werden, um im Prinzip weiterverarbeitet zu werden. Das heißt, wir brechen eigentlich diese großen Datenmengen in digestable Bits, das heißt leicht verdauliche Textblöcke auf, die dann im Prinzip im nächsten Schritt in einer sogenannten Vektordatenbank abgelegt werden.
Florian Polak: 00:11:38,810 –> 00:12:31,550
Sie sind Datenbanksysteme, die sehr gut geeignet sind, Inhalte miteinander zu vergleichen. Was wird da gemacht? Diese Chunks, die wir gemacht haben, also diese Textblöcke, werden umgewandelt in einen mathematischen Wert. Eigentlich. Und dieses System beendet diese ganzen Textblöcke in diese mathematischen Punkte, auf diese Vektorbar datenbank ab. Und wir messen dann eigentlich die Distanz zwischen zwei Textblöcken. Also wie ähnlich sind diese Aussagen sich zueinander? Wenn jetzt also eine Forschungsfrage nachgestellt wird, können Sie diese Anfrage oder auch eine Zusammenfassung haben wollen. Wird das auch umgewandelt in einen sogenannten Junk und dann abgelegt auf dieser Datenbank? Das heißt, wir können dann wissen, welche Textblöcke oder welche Informationen sind relevant?
Florian Polak: 00:12:32,210 –> 00:13:09,660
Um Ihre Frage zu beantworten. Gucken Sie sich technisch, wie das ganze System funktioniert hat ein paar Vorteile. Erstens mal dadurch, dass wir das Aufbrechen in diese Textblöcke, ist das System sehr performant. Ist das auch. Bei sehr großen Studien kriegen sie relativ rasch die Ergebnisse. Und es ist, weil eben wirklich nur diese Textblöcke herangezogen werden, die relevant sind für die Studie. Wir können auch mit einer gewissen Wahrscheinlichkeit sagen Wie relevant ist eine Aussage von einem Studienteilnehmer? Um Ihre Frage zu beantworten, zeige ich Ihnen nachher noch mal ganz gleich und wir können auch eine Rückverfolgbarkeit nehmen, was die keinen nimmt.
Florian Polak: 00:13:09,680 –> 00:13:52,040
Um die Frage zu beantworten, weil wir eben genau wissen, welche Textbausteine herangezogen wurden, um die Frage die Antwort zu formulieren. Finden Sie, und das ist im Prinzip genau dieses Thema, wie man eine inhaltliche Analyse sehr schnell machen kann. Wie würde das jetzt in der Praxis eigentlich für Sie aussehen? Auch schon ein. Ein Beispiel zum Beispiel wäre, dass Sie sagen okay, Sie können einen Ex hochladen, wo Sie Ihre gesamte Studien drin haben mit den verschiedenen Aussagen frei Textnennungen beispielsweise auch teilweise was Transkript schon aufgebrochen. Also Excel, können Sie das Ganze hochladen. Wir akzeptieren teilweise auch SVS Dateien, um im Prinzip das Ganze hochzuladen in unser System, was das System im Hintergrund dann macht.
Florian Polak: 00:13:52,040 –> 00:14:34,670
Das bricht eben diese Aussagen alle auch auf diese Textstelle und legt sie im Prinzip in einer eigenen Vektordatenbank für diese Studie ab. Geht natürlich auch mit einer EBA Schnittstelle, so dass das im Prinzip direkt angedockt ist und sie auf einen Knopf drücken und das rüberspielen. Das müssten wir uns da im konkreten Fall einfach anschauen. Der nächste Schritt ist, dass Sie dann eigentlich auswählen. Okay, welche Studie möchte ich jetzt gerade auswerten, drücken drauf und stellen tatsächlich Ihre Forschungsfragen. Da sind Sie sehr frei, wie Sie die Fragen formulieren. Grundsätzlich, dass das System eben machen wird. Es wird alle relevanten Informationen zusammensuchen, um Ihre Frage zu beantworten, Generiert daraus die Antwort auf Ihr, auf Ihre Forschungsfrage.
Florian Polak: 00:14:35,180 –> 00:15:14,840
Wir können auch tatsächlich so Sachen gemacht werden wie Was haben die weiblichen Teilnehmer dieser Studie tatsächlich zu diesem Thema gesagt? Weil wir können nämlich auch bei da bei diesen Textblöcken gewisse Metadaten hinterlegen, also beispielsweise, dass das jetzt eine Aussage von einem weiblichen Studienteilnehmer war. Das Ganze kann aggregiert werden, wird zusammengefasst und wird Ihnen als Antwort rausgegeben. Und Sie haben die Originaltext stellen, die am relevantesten sind, um Ihre Frage zu beantworten. Das schaut dann so aus Sie haben eine gewisse Relevanz da drinnen, wo Sie dann tatsächlich sehen können, okay, welche Aussagen wahr, hat das System herangezogen. Das ist jetzt hier ein Beispiel, weil das eine sehr kleine Studie war.
Florian Polak: 00:15:14,840 –> 00:16:01,790
Aber grundsätzlich kann das sind das üblicherweise was eingeschränkt auf die best passendsten 50 Aussagen und Sie haben natürlich einen Link direkt zu dieser Stelle. Ob das jetzt ein Transkript ist oder Beziehungsweise eine Stelle in einem Transkript oder ob das tatsächlich ein Excel Pfeil ist, wo Sie dann zu dieser jeweiligen Zelle springen, ist im Prinzip egal. Wir verlinken die Informationen, die Sie grundsätzlich in das System eingespielt haben und Sie haben eine leichte, einfache Möglichkeit, im Prinzip diese Aussagen zu überprüfen, indem Sie einfach über dieses eine Symbol drübergehen und sehen die Originalinformationen zu diesem Thema, zu dieser Aussage, dass je nachdem, was für Informationen da noch drinnen sind, inklusive Metadaten usw, kann man da alles relativ gebündelt navigieren.
Florian Polak: 00:16:02,150 –> 00:16:45,570
Aber das sind die Originaltexte. Das Spannende auch an der Tafel ist eben diese Wahrscheinlichkeit. Sie haben damit eine gewisse Überprüfbarkeit. Wie relevant ist ein Inhalt für die Beantwortung Ihrer Frage, um einfach zu sehen okay, wie gut ist das System in Ihrer Frage zurechtgekommen? Weil wie man Fragen formuliert, macht tatsächlich einen sehr großen Unterschied aus. Ähm, letzter Punkt Wir haben tatsächlich jetzt in den letzten paar Monaten ein paar Tests gemacht. Grundsätzlich ist es möglich, auch mehrsprachige Studien zu führen. Sprich man kann eine Frage auf Deutsch stellen und hat in seinen Daten sowohl französische Teilnehmer, englische Teilnehmer und beispielsweise polnische Teilnehmer.
Florian Polak: 00:16:45,570 –> 00:17:31,010
Dass man tatsächlich eine konkrete Studie gemacht haben, die das System übersetzt dann die Originalantworten der Teilnehmer automatisch in die Sprache, in der sie die Frage gestellt haben, gibt Ihnen dann die Antwort raus, basierend auf dem und verlinkt aber die Originaltext stellen dann in der jeweiligen Sprache, sodass Sie im Prinzip diese Studie auch tatsächlich mehrsprachig führen können. Ähm, hier, wir haben. Ich muss dazu sagen, wir haben nicht alle Teilsprachen getestet, die ich oben angeschrieben habe, Haben wir getestet. Bei denen wissen wir, dass es funktioniert. Im Regelfall würde ich sagen, romanische Sprache funktionieren tendenziell ein bisschen besser. Wir haben es noch nicht getestet mit beispielsweise Chinesisch, schlicht und einfach, weil wir auch intern nicht die Leute haben, die sie überprüfen können.
Florian Polak: 00:17:31,340 –> 00:18:12,000
Das heißt, das wäre ein Thema, wo wir uns das anschauen müssten. In Theorie sollten auch mehrere Sprachen eigentlich möglich sein, außer die genannten hier bei der Spracherkennung sind wir auch auf diese Sprachen mittlerweile eingeschränkt. Aber natürlich, wenn Sie schriftliche Daten hier einspielen und zum Beispiel chinesische Umfragen gemacht haben, müssten wir uns anschauen, wie gute Ergebnisse sind. Am besten natürlich mit jemandem, der Chinesisch kann. Natürlich können Sie das kombinieren mit anderen Produkten, die wir haben. Also als Beispiel Wir bieten ja im Prinzip quantitative Kodierung an, dass sie im Prinzip diese Freitagsnennungen zuerst tatsächlich kodieren, diese Ergebnisse dann anreichern, damit und später dann das Ganze noch mal auszuwerten.
Florian Polak: 00:18:12,330 –> 00:18:56,990
Man kann natürlich Kombinationen von dem machen, genauso gut natürlich in der qualitativen Auswertung. Wir haben ja Transkriptionen, bieten wir natürlich auch an und nachher auch noch die Möglichkeit, Aussagen aus Texten zu extrahieren und dann gebündelt als Geschenk so vorzubereiten, dass man es im nächsten Schritt mit solchen Sachen tatsächlich noch weiter auswerten kann. Datenschutz ist natürlich auch ein sehr, sehr wichtiges Thema. Grundsätzlich, wie vorhin erwähnt, Wir garantieren Ihnen, dass die Daten ausschließlich in Deutschland verarbeitet werden. Grundsätzlich Wir verarbeiten die Daten so, wie Sie das wünschen. Es gibt auch noch einmal die Möglichkeit, natürlich einzustellen, wann automatisch Daten wieder aus dem System gelöscht werden, wann im Prinzip was mit den Daten nachher passieren soll.
Florian Polak: 00:18:57,350 –> 00:19:42,770
Da sind wir sehr, sehr frei und je nachdem, wie der Kunde das möchte, können wir uns da natürlich anpassen. Ja, auf individuellen Wunsch. Was wir auch noch anbieten, sind unsere Server in Deutschland. Aber das hatten wir schon einmal, dass wir auch unseren Server in einem anderen Land aufgebaut haben. Schlicht und einfach, wenn der Kunde das gebraucht hat. Aus Datenschutzgründen. Ist möglich, ist aber ein Thema, wo wir einfach drüber sprechen müssen. Grundsätzlich gibt es zwei mögliche Pakete. Das eine Paket, das wir machen, was sehr viel in der Marktforschung verwendet, ist das On Demand Paket. Das heißt, Sie zahlen tatsächlich nach Menge der Datensätze oder pro Projekt, sind damit an keine Bindung gebunden und können das im Prinzip ad hoc nutzen, wann immer Sie, wann immer Sie das brauchen.
Florian Polak: 00:19:43,160 –> 00:20:24,840
Oder das Premiumprodukt, wo Sie sagen okay, Sie haben einen jährlichen Fixpreis, da ist es uns auch egal, wie viele Studien drüber laufen. Sie haben natürlich damit auch noch mal deutlich Mehrwert, weil sie im Prinzip Rabatte bekommen und natürlich noch mehr Service als im On Demand Bereich. Das wollte ich schon vorher erwähnt grundsätzlich die Transkription und nach aber auch die Auswertung. Die qualitative ist natürlich bei jeder Art von ON, von Sprachdaten bzw Videodaten natürlich auch relevant, dass sie diese Sachen in Text umwandeln können, um das Ganze nachher abzuwandeln. Das war’s auch schon von meiner Seite. Jetzt würde ich vielleicht auch die Fragen kurz eingehen.
Florian Polak: 00:20:24,990 –> 00:21:07,110
Ich habe so ein paar Sachen schon gesehen. Wunderbar. Die erste Frage war Beschränkt sich das System auf die Auswertung von allen Communities oder ist möglich eine Kombination zu buchen aus Auswertungen von anderen Communities, Communities bzw Auswertung, offene Nennung aus qualitativen Fragen mit quantitativen Fragebögen? Ja, das ist möglich. Also grundsätzlich das System ist geeignet, wirklich den letzten Schritt zu machen, wenn Sie die Daten schon vorbereitet haben. Sie können unser anderes Modul verwenden, wo Sie im Prinzip tatsächlich beispielsweise Sie haben Interviews, diese Interviews transkribieren, dann über unser qualitatives Codierungsstool im Prinzip aufzubrechen in die jeweiligen Kernaussagen und dann im Prinzip das Ganze auszuwerten.
Florian Polak: 00:21:07,110 –> 00:21:56,280
Das ist möglich, kann man auf jeden Fall machen. Ist es möglich, vor der Beauftragung einen Test Case zu machen? Ja, Sie können das natürlich ausprobieren. Sehr gerne. Kontaktieren Sie mich dazu einfach. Der erste Test ist natürlich kostenlos. Kann das System bei mehr Länderstudien auch Vergleiche zwischen den Ländern ziehen? Ja, geht auch. Man muss sich dazu nur überlegen, wie man das Ganze strukturiert, also im Hintergrund. Wie wir das machen, ist, wenn Sie eine Studie hochladen, werden wir das im Prinzip in einen anderen Ordner im System ablegen. Und dann können Sie sich aussuchen, was tatsächlich Entweder, dass Sie nur gegen diese beispielsweise französische Studie Fragen stellen, oder wenn Sie Vergleichen machen wollen, nehmen Sie sowohl den Ordner mit der französischen Studie oder der deutschen Studie und stellen vergleichende Fragen gegenüber diesen Zahlen.
Florian Polak: 00:21:56,730 –> 00:22:37,970
Geht alles, müsste man nur strukturell sich überlegen, wie man das am besten aufsetzt. Können wir gerne unterstützen, um so was zu machen? So, dann war im Chat noch ein paar Sachen. Wie viele Informationen ausholen, benötigt das System mindestens um zuverlässig arbeiten zu können. Grundsätzlich ist schwer zu sagen, das kann man wahrscheinlich nicht so wirklich kontrollieren. Das heißt, ich würde da einfach sagen grundsätzlich, man kann eine Aussage hochladen und dann eine Frage dagegenstellen. Das ist wahrscheinlich nicht besonders sinnvoll. Aber sie sind ja nicht eingeschränkt. Das heißt, das System wird halt mit entweder zum Beispiel einem Transkript arbeiten oder halt sehr, sehr vielen Excel Daten und Antworten.
Florian Polak: 00:22:38,450 –> 00:23:27,730
Da kommt ein bisschen darauf an, je mehr Daten Sie natürlich einspielen, ein System, desto wahrscheinlich statistisch relevanter ist das Kann ich nicht selber beurteilen. Müsste man sich einfach den konkreten Fall anschauen? Was verbirgt sich hinter dem Relevanzwert, der das System für vergibt? Wie ist diese zu verstehen? Sehr gute Frage. Grundsätzlich Was ist diese Relevanz? Das ist die Distanz, die mathematische von diesem in dieser Vektordatenbank. Zu Ihrer Frage Das heißt, wenn wir noch mal zurückgehen. Wie weit ist diese Aussage von diesem Studienteilnehmer? Von der Distanz her weit entfernt, inhaltlich weit entfernt von Ihrer Frage. Das ist das System Im Prinzip, das die Relevanz misst, ist ein Prozentueller Wert, den man dann mathematisch ganz gut ausrechnen kann.
Florian Polak: 00:23:28,090 –> 00:23:56,830
Aber das ist im Prinzip genau dieser Aspekt, der technisch funktioniert, um. Um das im Prinzip zu mappen. Das heißt, im ersten Schritt wird das Ganze, wie gesagt mathematisch umgewandelt und dann wird einfach die Distanz gemessen, um diese Relevanzwerte benennen zu können. Finde ich die Aufzeichnung später irgendwo für die Chefs. Danke. Ja, ich kann Ihnen auch gerne die natürlich im Anschluss die Präsentation schicken Aufzeichnen auf Marktforschung. Punkte Eens müssten die Kollegen dann beantworten.
Sabrina Gehrmann: 00:23:57,520 –> 00:24:04,810
Genau. Das Ganze wird aufgezeichnet. Das packen wir später bei uns in die Mediathek. Deswegen. Das können Sie alles noch mal nachschauen.
Florian Polak: 00:24:05,960 –> 00:24:54,570
Noch werden Dialekte und Schreibfehler erkannt und gehen diese Infos dann verloren. Also grundsätzlich. Das System ist relativ robust, was Schreib oder Grammatikfehler angeht. So, wenn es. Ausreicht, um den Kontext aus diesem Satz oder diesem Absatz zu extrahieren, würde es das System richtig zuordnen. Da kann es natürlich manchmal Fehler geben, je nachdem, wie diese Sachen formuliert sind. Wir kennen sehr gut mittlerweile aus der quantitativen Kodierung, wo natürlich haufenweise Grammatik und Rechtschreibfehler drinnen sind. Üblicherweise ist es so, dass es erstaunlich viele erkennt. Können wir natürlich gerne in einer Probe Testlauf einfach mal ausprobieren. Können Sie gerne auch mit vielen Rechtschreibfehlern und Grammatik Fehlern das einspielen lassen?
Florian Polak: 00:24:54,840 –> 00:25:31,350
Sie werden sehen, dass das System eigentlich das ganz gut erkennen könnte. Wunderbar. Und Dialekte? Ja, für Dialekte kann ich Ihnen ist vor allem relevant in der Spracherkennung. Da können wir uns fokussieren auf möglichst vor allem deutsche Dialekte und Akzente gut zu können. Ich selber bin Österreicher, wie Sie es vielleicht hören. Also auch österreichische Akzente gehen grundsätzlich ganz gut. Ich würde sagen, je weiter westlich man geht, also Richtung der Schweiz, desto schwieriger wird es. Wir haben tatsächlich noch massive Probleme in der Spracherkennung. Nicht nur wir, sondern alle. Leider. Um die Schweizer zu verstehen. Also Schweizerdeutsch ist noch ein ungeklärtes Thema.
Florian Polak: 00:25:31,770 –> 00:26:08,130
In geschriebenen Texten ist es dann tatsächlich ein bisschen einfacher. Wiederum, weil da einfach wiederum das System einfach versucht, den Kontext aus diesem Satz zu erkennen. Im Regelfall sollte das ein bisschen besser funktionieren. Schweizerdeutsch haben wir auch da aber noch nicht getestet. Das müsste man schauen. In Ihrer zitierten Studie Welche oder wie viele Daten hatten Sie hierfür? Das war Ich kann es nicht auswendig sagen, aber ich glaube, wir hatten auf jeden Fall Aussagen von über 200 Teilnehmern. Das waren an sich eine große Studie, die wir da hatten. Das heißt, es war. Es war eine Excel Datei, alle waren schön gemischt, also hatten wir im Prinzip viel Text Antworten auf.
Florian Polak: 00:26:08,310 –> 00:26:44,670
Ich glaube, es waren über 50 Fragen. Es ging über mehrere Tage. Das Ganze, teilweise auch Audioaufzeichnungen von den Teilnehmern, die dann transkribiert wurden und auch noch einmal eingespielt würden. Also es war schon eine ziemliche Monsterstudie, die wir da gemacht haben und auf verschiedenen Sprachen wurde das Ganze ausgewertet haben. Aber auch Ihr Vorschlag Probieren Sie es einfach gerne mit uns aus. Sie haben meine Kontaktdaten. Jetzt können Sie jederzeit gerne schreiben. Wir können gerne eine Probe Durchlauf machen und noch einmal im Detail schauen, ob das für Ihre Studie geeignet ist. Und wir können das gerne einfach mal ausprobieren.
Florian Polak: 00:26:46,050 –> 00:27:21,230
So, und ich habe jetzt gleich noch ihm Fragen und Antworten. Gibt es noch was? AT the dam. Wie sieht es mit der Auswertung von quantitativen Daten in Kombination mit qualitativen Aussagen und Fragebögen an? 50 % der Befragten fanden XY nicht so gut und den offenen findet man dann eine Erklärung, warum das so ist. Das ist tatsächlich ein sehr gutes Beispiel, wo es gut funktioniert mit dem System, weil wir dann den Konnex zwischen diesen beiden Fragen herstellen und dann auch die Aussage miteinander kombinieren können. Tatsächlich, das ist auch der Bereich, wo das Ganze recht spannend wird. Können wir gerne ausprobieren.
Florian Polak: 00:27:21,410 –> 00:28:08,570
Mein Vorschlag wäre Kontaktieren Sie uns einfach und wir können das einfach mal testen. Welche Übersetzungssoftware ist integriert? Grundsätzlich. Teilweise geht es sogar mit den mit der KI selber. Dass die vom Kontext her viel verschiedenen Sprachen versteht, einfach aufgrund der Trainingsdaten, die da drinnen sind, ist in vielen verschiedenen Sprachen drinnen. Wir haben unterstützend auch noch die BL, die meiner Meinung nach eigentlich die besten Übersetzungen und Übersetzungsmodule hat, aber grundsätzlich im Regelfall auf textueller Ebene ist das System tatsächlich meistens sogar schlau genug, tatsächlich das Ganze miteinander zu übersetzen und den Kontext daraus zu verstehen. Kommt darauf an, wir würden die Bälle dann zuschalten, wenn wir sehen, dass der Kontext nicht herausgelesen werden kann.
Florian Polak: 00:28:08,900 –> 00:28:23,430
Das wäre zum Beispiel eine Möglichkeit, wenn man Sprachen hat wie Chinesisch oder Arabisch, die doch sehr, sehr anders sind. Dann würden wir wahrscheinlich auf die Welt zurückgreifen. Ein noch. So? Ich glaube, das war’s, oder?
Sabrina Gehrmann: 00:28:24,150 –> 00:29:09,000
Ja. Erfolgreich. Alle Fragen beantwortet. Deshalb vielen lieben Dank, Florian, dafür. Und ich denke, wenn Sie noch Fragen im Nachgang haben, hier sind ja die Kontaktdaten. Deswegen gerne einfach melden. Deswegen würde ich unter die Kühe und als Häschen jetzt einen Strich machen und möchte Ihnen, liebe Zuschauerinnen und Zuschauer und natürlich auch Florian noch den Hinweis geben, dass wir Ende, oder? Ja, ab Mitte Februar stehen weitere spannende Webinare bei uns im Haus an, da können Sie sich einfach wieder anmelden. Alles kostenfrei, versteht sich. Auf dem gewählten, gewohnten Weg über Marktforschung punkt.de unter der Rubrik Webinare. Dort gerne einfach mal reinklicken.
Sabrina Gehrmann: 00:29:09,000 –> 00:29:32,010
Da würde ich mich freuen, den oder die eine oder andere noch wieder begrüßen zu dürfen. Zum nächsten Event. Ja, aber jetzt würde ich sagen, haben wir es auch geschafft für den Vormittag und entlassen gleich alle in die Mittagspause. Bevor du gerne die Schlussworte wählen darfst, sage ich von meiner Seite aus schon mal vielen lieben Dank für Ihre Aufmerksamkeit, liebe Zuschauerinnen und Zuschauer und wünsche gleich eine schöne Mittagspause.
Florian Polak: 00:29:33,080 –> 00:29:34,600
Gut. Vielen Dank. Danke schön.
Sabrina Gehrmann: 00:29:35,470 –> 00:29:35,860
Tschüss.
Online-Community-Daten – ein Meer voller Einsichten
Der wahre Wert von Online-Community-Daten liegt in ihrer Fähigkeit, tiefgreifende Einblicke in die Gedankenwelt der Verbraucher zu gewähren. Diese Daten gehen weit über quantitative Statistiken hinaus und umfassen qualitative Elemente wie Freitextantworten sowie multimediale Inhalte, was eine ganzheitliche Analyse ermöglicht. Die Herausforderung besteht in der Komplexität und Diversität dieser Daten, die eine effiziente und effektive Auswertung erforderlich machen.
Tucan.ai: Neudefinition der Datenauswertung
Tucan.ai ermöglicht Marktforschenden, Online-Community-Daten als Ganzes zu verarbeiten. Mit eigens entwicklten KI-Algorithmen kann Tucan.ai Text-, Video- und Audioinhalte in nur wenigen Minuten transkribieren und analysieren. Die USP liegt dabei in der Kombination aus vielseitiger Datenverarbeitung, präziser Analytik und Datensicherheit. Die KI-gestützte Plattform ist speziell darauf ausgerichtet, komplexe Datenmengen nicht nur schnell zu erfassen, sondern auch tiefgreifend und kontextuell und mit Quellenreferenzen der Antworten zu analysieren. Die so generierten Einblicke ermöglichen fundiertere Entscheidungen und verschaffen den Unternehmen im konkurrierenden Marktumfeld einen signifikanten Wettbewerbsvorteil.

Effienz gepaart mit tiefgehender Analyse
Tucan.ais Technologie ist darauf ausgerichtet, Ergebnisse schnell zu liefern, ohne dabei an Relevanz und Genauigkeit einzubüßen. Der Schlüssel dazu ist die Fähigkeit von Tucan, große Mengen von Textdaten effizient zu verarbeiten. Durch das Aufbrechen der Texte in kleinere, thematisch zusammenhängende Blöcke (sogenannte "Chunks") und die Verwendung einer Vektordatenbank kann Tucan relevante Informationen schnell identifizieren und für die Beantwortung von Forschungsfragen nutzen. Dieser Prozess ermöglicht es, die Daten gründlich und effizient zu analysieren, ohne dabei auf die Erzeugung von nicht existierenden Informationen zurückzugreifen.
Transparente und verlässliche Ergebnisse, ohne KI-Halluzination
Ein wichtiges Merkmal der Software ist die Quellenreferenzierung jeder generierten Antwort. Dadurch wird eine hohe Transparenz der Auswertungen gewährleistet und das Vertrauen in die Zuverlässigkeit der KI-Analysen gestärkt. Außerdem die stellt Tucan.ai sicher, dass die KI nur auf der Grundlage der eingespeisten Daten Antworten generiert und sich nicht auf externe Daten oder Erfindungen stützt. Ein entscheidendes Detail, gerade wenn es um vertrauliche und präzise Auswertungen geht.

Keine Begrenzung der Datenmengen
Ein weiterer Vorteil von Tucan.ai besteht darin, dass es keine Beschränkung hinsichtlich der Menge an Daten gibt, die hochgeladen werden können. Ganz gleich, ob Gigabyte oder Terabyte – die Systemperformance bleibt unverändert hochwertig.
Datensicher und DS-GVO-konform
Sicherheit und Datenschutz nehmen einen hohen Stellenwert ein, insbesondere wenn es um sensible Forschungsdaten geht. Eine Garantie, die Tucan.ai bietet, ist die ausschließliche Verarbeitung der Daten auf Servern in Deutschland. Dies gibt Unternehmen das Vertrauen, dass ihre Daten entsprechend der DS-GVO behandelt werden.
Wettbewerbsvorsprung mit KI
Die Verwendung von Tucan.ai in Projekten bedeutet, dass Marktforscher sich nicht mehr mit der langwierigen Aufgabe der Datenauswertung belasten müssen. Stattdessen können sie ihre Expertise nutzen, um tiefere Einblicke zu gewinnen und strategische Geschäftsentscheidungen zu treffen. Durch diese Reorganisation von Ressourcen können Unternehmen mehr Projekte gleichzeitig bearbeiten und ihre Kapazitäten erweitern.
Tucan.ai ist ein Blick in die Zukunft der Marktforschung, in der die Automatisierung und intelligente Analyse von Online-Community-Daten Unternehmen zu enormen Wettbewerbsvorteilen verhelfen kann. Die Kombination aus Technologie, Benutzerfreundlichkeit und Präzision macht Tucan.ai zu einem unverzichtbaren Werkzeug in der modernen Marktforschung.
Sichern Sie sich Ihren Wettbewerbsvorsprung!
MAXQDA vs. Tucan.ai: Ein analytischer Tiefeinblick in moderne Marktforschungstools
MAXQDA – Ein etablierter Name in der Datenanalyse
MAXQDA gilt als eine robuste Marktforschungssoftware, die sowohl qualitativen als auch quantitativen Forschern eine strukturierte Analyseumgebung bietet. Ihre leistungsstarken Funktionen für das Transkribieren von Interviews und die automatische Transkription von Audio- und Videodateien machen sie zu einem bevorzugten Tool für ausführliche Datenanalysen. Mit synchronisierten Zeitstempeln und einem vielseitigen Codierungssystem ist MAXQDA besonders geeignet für das qualitative Codieren und tiefgehende Datenuntersuchungen mittels Text- und Wortfrequenzsuche.

Tucan.ai – Die KI-gestützte Innovation in der Marktforschung
Im Kontrast zu MAXQDA zeichnet sich Tucan.ai durch seine Fokussierung auf KI-gestützte Effizienzsteigerung aus. Das Tool, speziell entwickelt für die qualitative und quantitative Marktforschung, automatisiert und vereinfacht die Codierung von Freitextantworten nachhaltig. Mit Features zur Auswertung basierend auf Interview-Leitfäden und der Automatisierung von Studienberichten bietet Tucan.ai eine einzigartige Kombination aus Effizienz und Präzision für Marktforschungsunternehmen.

Vergleich der Funktionen: MAXQDA AI Assist VS Tucan.ai
Die technischen Merkmale und Funktionen eines Analysewerkzeugs sind entscheidende Faktoren für seine Wirksamkeit. Im direkten Vergleich der Funktionen von MAXQDA und Tucan.ai werden die Vorzüge und Grenzen beider Anwendungen deutlich.
Übersicht
| Feature | ||
|---|---|---|
| Transkription | Hochpräzise KI-gesteuerte automatische Transkription und Analyse | Manuelle und KI-unterstützte Transkription mit dem AI Assist Add-on |
| KI-unterstützte Analyse | Umfassende KI-Funktionen ohne zusätzliche Anschaffung | Eingeschränkte KI-Funktionalitäten - erfordert den Kauf eines Add-ons |
| Kodierung und Analyse | Vollständig automatisierte Kodierung, die den manuellen Arbeitsaufwand erheblich reduziert | Erweiterte qualitative und quantitative Kodierungswerkzeuge; manueller Aufwand erforderlich |
| Datensicherheit und Compliance | Garantierte Datenlokalisierung mit Cloud- oder On-Premise-Einrichtung; Ort der Datenverarbeitung via Cloud: Deutschland | Datensicherheit hängt von einem Drittanbieterdienst (OpenAI) für KI-Funktionen ab |
| Sprachliche Unterstützung | Unterstützt mehrere Sprachen, vorteilhaft für internationale Nutzer | Unterstützt mehrere Sprachen, vorteilhaft für internationale Nutzer |
Stand: November 2023
Buchen Sie einen kostenlosen Beratungstermin!
Automatische Transkription & KI-basierte Auswertung von qualitativen Interviews
MAXQDA und Tucan.ai bieten jeweils eine Lösung für die Transkription und Auswertung von qualitativen Interviews, allerdings mit unterschiedlichen Ansätzen und Technologien.
MAXQDA Transkriptionsfunktionen: MAXQDA ermöglicht die manuelle Transkription von Audio- und Videodateien und bietet Unterstützung durch den Einsatz von KI-basierter Transkription durch das AI Assist Add-on. Diese Funktionalität erfordert eine aktive MAXQDA 24 Lizenz und ist damit an eine kostenpflichtige Erweiterung gebunden. Während das Tool bei der Transkription hilfreiche Features wie automatischen Sprecherwechsel, Zeitstempel und Autovervollständigung bietet, stellt der kostenpflichtige Charakter des AI Assists eine zusätzliche Hürde dar.
Tucan.ai's KI-getriebene Lösung: Im Gegensatz dazu zielt Tucan.ai darauf ab, den gesamten Transkriptionsprozess zu automatisieren und stellt eine Genauigkeit von bis zu 95% in Aussicht. Darüber hinaus ermöglicht Tucan.ai die Analyse von Interviews basierend auf spezifischen Kriterien und Leitfäden, die durch fein abgestimmte KI-Algorithmen unterstützt werden. Diese Tiefe und Anpassungsfähigkeit der Analyse sparen Forschern nicht nur Zeit, sondern erhöhen auch die Präzision der Ergebnisse.
Automatisierte Codierung
Die Codierung von qualitativen Daten ist ein wesentlicher Schritt in der Analyse. Beide Programme bieten Lösungen zur Vereinfachung dieses Prozesses, unterscheiden sich jedoch in ihrem Ansatz und ihrer Effizienz.
MAXQDAs Ansatz zur Codierung: MAXQDA erlaubt es Nutzern, Textpassagen manuell zu kodieren und bietet unter anderem deduktive und induktive Codesysteme an. Das Erstellen und Verwalten der Codes wird durch eine Vielzahl von Farben und Schlagworten unterstützt, was die Organisation qualitativer Daten erheblich erleichtert. Dennoch kann die Codierung zeitaufwändig sein und eine umfassende Einarbeitung in das Tool erfordern – eine Herausforderung, die insbesondere für neue Nutzer abschreckend sein könnte.
Tucan.ais innovation bei der automatisierten Codierung: Tucan.ai revolutioniert den Codierungsprozess durch die Verwendung von Künstlicher Intelligenz, die den Vorgang der Codierung automatisiert und beschleunigt. Anstatt manuell Codes zuweisen zu müssen, verwendet Tucan.ai maschinelles Lernen, um Textantworten zu analysieren und Codes zuzuteilen, was den Prozess nicht nur beschleunigt, sondern auch die Wahrscheinlichkeit von Fehlzuweisungen reduziert. Dieser KI-getriebene Ansatz schafft einen nahtlosen Übergang von der Erfassung und Transkription von Daten bis hin zu deren tiefgehender Analyse und Berichterstellung – ein deutlicher Vorteil gegenüber traditionellen Methoden.
Datenschutz und Sicherheit
Bei der Auswahl von Analyse-Tools für die Marktforschung ist neben der Funktionalität auch der Datenschutz ein ausschlaggebender Faktor. Forschungsdaten können sensible Informationen enthalten, deren Schutz nicht nur aus ethischer Sicht, sondern auch aufgrund gesetzlicher Bestimmungen wie der DSGVO höchste Priorität hat. Datenschutzfunktionen bei MAXQDA: MAXQDA betont den Datenschutz durch verschiedene integrierte Funktionen, die dabei helfen, persönliche Daten der Teilnehmenden zu schützen und die Anonymität zu wahren. Da MAXQDA jedoch insbesondere für sein Add-on AI Assist auf OpenAI-Dienste zurückgreift, ist es möglich, dass Daten außerhalb des europäischen Rechtsraums in die USA übermittelt werden. Dieses Szenario ist insbesondere für Forschende relevant, die strengen Datenschutzgesetzen unterliegen und deshalb Wert auf die Speicherung und Verarbeitung von Daten innerhalb bestimmter geopolitischer Grenzen legen. Tucan.ais Engagement für Datensicherheit: Tucan.ai hingegen macht Datensicherheit zu einem Kernbestandteil seiner Service-Philosophie. Mit der Möglichkeit, Daten sowohl in der Cloud als auch On-Premise zu speichern, gibt Tucan.ai den Nutzenden volle Kontrolle über ihre Daten. On-Premise-Lösungen sind entscheidend für Unternehmen, die es bevorzugen, ihre potenziell sensiblen Forschungsdaten auf ihren eigenen Servern zu behalten, komplett unter ihrer eigenen Verwaltung. So können etwaige Risiken, die bei der Cloudspeicherung auftreten können, effektiv vermieden werden. Zusätzlich bieten diese lokalen Lösungen oft anpassbare Sicherheitseinstellungen, die den spezifischen Sicherheitsrichtlinien eines Unternehmens oder einer Institution entsprechen. Die Balance zwischen Zugänglichkeit und Sicherheit: Sowohl MAXQDA als auch Tucan.ai befinden sich in der Herausforderung, ihre Software einerseits für Nutzende leicht zugänglich zu machen und andererseits höchste Sicherheitsstandards zu gewährleisten. Während MAXQDA eine große Nutzerbasis hat und ständig daran arbeitet, seine Datenschutzmaßnahmen zu verbessern, richtet Tucan.ai seinen Blick auf zukünftige Technologien und bietet innovative Sicherheitslösungen an, die besonders dafür entwickelt sind, den Anforderungen der sich ständig weiterentwickelnden Sicherheitslandschaft gerecht zu werden.
Schlussfolgerung: Die richtige Wahl in einer sich wandelnden Marktforschungslandschaft
Der Direktvergleich zwischen MAXQDA und Tucan.ai beleuchtet die sich rapide entwickelnde Welt der Marktforschungstools, in der traditionelle und KI-gestützte Ansätze nebeneinander existieren. Während MAXQDA seine bewährten Qualitäten und eine langjährige Vertrautheit in der Forschungsgemeinschaft vorweisen kann, überzeugt Tucan.ai als Vorreiter einer technologischen Wende, die die Grenzen der Effizienz und Präzision in der Marktforschung neu definiert. Empfehlung für eine zukunftsweisende Marktforschung: Verglichen mit der traditionellen Zuverlässigkeit von MAXQDA, stellt Tucan.ai eine attraktive Option dar, insbesondere für Unternehmen und Forscher, die bereit sind, den Schritt hin zu einer datengesteuerten Zukunft zu wagen. In einer Zeit, in der Geschwindigkeit, Genauigkeit und Datensicherheit integraler Bestandteil jeder Forschungsarbeit sind, eröffnet Tucan.ai Möglichkeiten, um qualitative Erkenntnisse in quantifizierbaren Erfolg zu übersetzen. In der Synthese der Vergleichsanalyse bleibt festzuhalten, dass die Wahl zwischen MAXQDA und Tucan.ai nicht lediglich eine Entscheidung zwischen zwei Tools ist, sondern eine Entscheidung darüber, auf welcher Seite der technologischen Innovation sich Forschende sehen. Indem sie sich für das Tool entscheiden, das am besten zu ihren Methoden, ihrer Ethik und ihrer zukünftigen Richtung passt, bestimmen sie den Kurs ihrer Forschungsprojekte und letztendlich ihres Beitrags zum Wissensfundus ihrer Disziplin.
Auf der Suche nach einer Enterprise Lösung?
Ob benutzerdefiniertes Datenmodell-Trainings, kundenspezifische Workflow-Integrationen, Cloud oder On-Premise, oder erweiterte Sicherheitsfunktionen, mit Tucan.ai ist alles möglich. Schneiden Sie Ihr Paket gemeinsam mit Ihrem persönlichen Kundenberater auf Ihre Bedürfnisse zu.
Buchen Sie einen kostenlosen Beratungstermin!