From data to insights: AI secrets for market research professionals
In an era where data is king, the integration of artificial intelligence (AI) into market research is revolutionizing the way we gather and interpret insights. In his recent webinar "From Data to Insights: AI Secrets for Market Research Professionals", Florian Polak, co-founder of Tucan.ai, provided a deep dive into the practical applications of AI in market research. This blog post offers a detailed summary of the webinar on martforschung.de, spotlighting the benefits AI solutions can bring to the industry.
"We know how crucial the transparency and reliability of the results provided by our AI is."

Interview Marktforschung.de with Florian Polak
Managing Director, Tucan.ai GmbH
Edit Content
Edit Content
AI based summary by Tucan.ai
Einführung und Überblick:
– Florian Polak, Geschäftsführer von Tucan.ai, führte durch das Webinar zur Woche der Marktforschung.
– Tucan.ai ist ein junges Unternehmen aus Berlin, spezialisiert auf die Extraktion relevanter Informationen aus Text-, Audio- und Videodateien für Marktforschungszwecke.
KI-Systeme und Anwendungen:
– Es wurde ein Überblick über KI-Systeme und deren Anwendung in der Marktforschung gegeben, inklusive Tipps und Tricks für den effizienten Einsatz.
– Tucan.ai bietet Produkte an, die es ermöglichen, KI-Technologien zur Effizienzsteigerung und zur Überholung der Konkurrenz einzusetzen.
Probleme und Lösungen bei KI-Systemen:
– Diskussion über gängige Probleme bei der Nutzung von KI-Systemen, insbesondere das Phänomen der “Halluzination” von KI, ungenaue oder oberflächliche Antworten und Datenschutzbedenken.
– Tucan.ai nutzt spezielle Technologien und Ansätze, um präzise und relevante Ergebnisse zu liefern und gleichzeitig Datenschutz und Sicherheit zu gewährleisten.
Anwendungsbereiche und Funktionen:
– Tucan.ai’s Software ermöglicht die Auswertung von Online-Communities, qualitative Kodierung von Interviews oder Gruppenstudien und quantitative Auswertung von Textdaten.
– Die Software unterstützt verschiedene Datenformate und bietet eine hohe Verarbeitungsgeschwindigkeit und Genauigkeit.
Datenschutz und Sicherheit:
– Tucan.ai garantiert, dass Daten ausschließlich in Deutschland verarbeitet werden und bietet verschiedene Kooperationsmodelle an, einschließlich On-Premise-Lösungen.
Preismodelle:
– Tucan.ai bietet flexible Preismodelle an, die auf Projektbasis oder als jährliche Pauschale gestaltet werden können, abhängig von den Bedürfnissen des Kunden.
Fragen und Antworten:
– Im Webinar wurden verschiedene Fragen der Teilnehmer beantwortet, unter anderem zur Verarbeitung von Dialekten, der Möglichkeit, Audiodateien zu testen, und zur Verarbeitung und Analyse von demografischen Daten in Verbindung mit offenen Antworten.
Abschluss:
– Das Webinar endete mit dem Angebot, bei weiteren Fragen Kontakt aufzunehmen und der Ankündigung, dass eine Zusammenfassung des Webinars zur Verfügung gestellt wird.
Edit Content
AI based transcript by Tucan.ai
Florian Polak: 00:00:02,950 –> 00:00:41,380
Schönen guten Tag. Hallo. Florian Polak ist mein Name hier von Tucan.ai. Willkommen bei unserem Webinar zur Woche der Marktforschung von Tucan.ai. Ich glaube, wir können schon anfangen. Ich werde Ihnen ganz kurz nur den Ablauf erklären. Ich werde Ihnen einen Überblick geben zu verschiedenen Themen im Rahmen der CI Forschung. Natürlich. Ähm, wir werden im Anschluss. Ich glaube, ich schätze mal, dass ich so 20 30 Minuten maximal brauchen werde. Wenn werden im Anschluss auch eine Fragerunde machen. Haben Sie in der Zwischenzeit Fragen? Bitte schreiben Sie die in unseren Chat einfach hinein und am Schluss, im Anschluss des Webinars, werde ich natürlich alle Fragen beantworten, die Sie im Chat gestellt haben.
Florian Polak: 00:00:42,400 –> 00:01:21,640
Wunderbar. Dann würde ich ganz kurz anfangen. Vielleicht ganz kurz zu mir. Florian Polak hier. Ich bin einer der Geschäftsführer von Tucan.ai. Mein Job, abgesehen davon Webinare zu halten, ist es mehr oder weniger eigentlich zu übersetzen, was unsere technische Abteilung alles macht. Wir sind ein junges Unternehmen aus Berlin, die mittlerweile seit fünf Jahren am Markt und haben uns darauf fokussiert, gerade im Bereich Marktforschung relevante Informationen aus einer großen Menge von Text oder auch aus Audio oder Videodateien im Prinzip zu extrahieren. Ich werde Ihnen einen kurzen Überblick jetzt mal geben. Wunderbar, wir fangen auch schon an, was werde ich in diesem Webinar alles machen?
Florian Polak: 00:01:22,360 –> 00:01:57,730
Ich werde ein bisschen eingehen auf KI Systeme und Begrifflichkeiten da drin in Ihnen versuchen simpel einen Überblick zu geben. Ohne jetzt zu sehr in die Details hier reinzugehen. Ich werde Ihnen vor allem aber auch ein paar Tipps und Tricks auf den Weg geben, worauf Sie vielleicht beim Arbeiten mit KI auch achten sollten. Und ich werde Ihnen natürlich auch zeigen, was wir grundsätzlich für Produkte anbieten und wie Sie entweder mit uns oder auch das selber im Prinzip aufbauen können, dass Sie KI Technologien bei Ihnen einsetzen und im Prinzip damit natürlich sehr, sehr effizient ihre Konkurrenz im Prinzip abhängen können.
Florian Polak: 00:01:59,660 –> 00:02:29,660
Was ist auf der Agenda? Hier eine kurze Vorstellungsrunde zu uns machen, was wir so machen, was wir grundsätzlich anbieten. Ich werde dann vor allem aber auch einen Fokus darauf legen, was für Probleme mit KI Systemen eigentlich sind, sondern was man da eigentlich ein bisschen achten sollte. Ich werde ein bisschen darauf eingehen, wie so grundsätzlich der Markt aktuell agiert und was gut daran ist und was vielleicht nicht so gut daran ist. Dann gebe ich Ihnen natürlich auch einen Überblick über unsere Software und werde Ihnen auch verraten, im Prinzip, was hinter unserem System steckt, wie wir das Ganze im Prinzip aufgebaut haben.
Florian Polak: 00:02:30,260 –> 00:03:08,210
Um Ihnen einfach nochmal einen Überblick zu geben, warum unser System in diesem Fall sehr gut geeignet ist für die Marktforschung. Dann natürlich zu guter Letzt noch ein kleines Thema über das Thema Datenschutz natürlich. Und Sicherheit ist sehr wichtig, gerade in der Auswertung von Studien und natürlich, was wir grundsätzlich für Preispakete haben, damit Sie den Überblick haben. Zu guter Letzt eine Fragerunde, wo sich alle Ihre Fragen beantworten werde, die Sie in diesem Chat stellen. Dann fangen wir auch schon kurz mal an, wir würden grundsätzlich in 2019 gegründet, sind ein Kleinunternehmen aus Berlin, haben mittlerweile 20 Mitarbeiter, ein Großteil davon natürlich in der Technikabteilung.
Florian Polak: 00:03:09,050 –> 00:03:51,800
Haben da eigene KI Spezialisten, die sich in den letzten vier, fünf Jahren eigentlich damit beschäftigt haben, solche Algorithmen und aber auch natürlich Infrastruktur dafür aufzubauen, mit dem Fokus immer mehr einer Analyse von Gesprächen, aber auch Texten gut hinbekommen. Wir haben uns fokussiert, Da wir ja als deutsches Unternehmen mit auch sehr öffentlichen oder sehr großen Unternehmen zusammenarbeiten, haben wir uns darauf fokussiert, eben auf sensible Informationen zu verarbeiten mit dem entsprechenden Sicherheits und Datenschutzstandards, die damit einhergehen, und haben hier aber auch in der Marktforschung mittlerweile auch recht große Kunden. Was kann man mit unserer Software machen? Ganz grob gesagt sind es drei Bereiche.
Florian Polak: 00:03:52,010 –> 00:04:38,180
Das eine ist im Prinzip Online Communities auswerten, das heißt wirklich Fragen an große Datenmenge zu stellen. Dann natürlich die qualitative Kodierung von Kern, von Interviews oder Gruppenstudien und natürlich auch vor allem bei frei Textnennungen, also Textdaten, im Prinzip Excel oder Textdateien quantitativ im Prinzip auszuwerten, wann immer Sie eine Freitagsnennung haben, das möglich auf einen einzelnen Code zu verdichten und dann im Prinzip das Ganze auszuwerten. Ähm, ja, grundsätzlich unsere. Wir haben einige Kunden hier in Deutschland mittlerweile die größten, die wir haben, ist einerseits die deutsche Bundeswehr, aber auch im Automobilsektor. Recht viel ist mittlerweile mit Porsche und Mercedes Benz und im öffentlichen Bereich vor allem auch natürlich Landtag.
Florian Polak: 00:04:38,180 –> 00:05:18,290
Mecklenburg Vorpommern ist einer unserer größten Kunden hier. Grundsätzlich die drei Bereiche. Was kann man da genau machen? Im qualitativen Forschungsbereich geht es vor allem darum, Interviews oder Gruppendiskussionen im Prinzip zu einerseits zu transkribieren, da damit haben wir ursprünglich mal angefangen haben eigene Spracherkennungsalgorithmen aufgebaut, wie Sie es vielleicht hören. Ich bin Österreicher, der auch verschiedene. Im Prinzip Akzente und Dialekte kann unser Algorithmus ganz gut verstehen. Das Ganze wird in Text gebracht und dann geht es darum, im Prinzip anhand eines Leitfadens oder Ihrer Fragen im Prinzip relevante Antworten zu extrahieren und zusammenzufassen und wieder zu verdichten. Das selbe Thema dann auch in der quantitativen Forschung.
Florian Polak: 00:05:18,290 –> 00:05:56,180
Hier geht es vor allem darum, dass man wirklich große Mengen von Antworten hat, also beispielsweise Kundenservice ist ein klassischer Fall, wo dann sehr, sehr viele Antworten in alle Richtungen natürlich gehen, wo man diese Textendungen dann verdichtet, im Prinzip mit einem entweder bestehenden Codeplan oder aber auch die KI tatsächlich selber Code Pläne finden zu lassen. Im Durchschnitt braucht es unser System für so circa 1000 Freitagsnennungen unter zwei Minuten. Das geht also relativ fix. Das Ganze dann natürlich die Community so auswerten. Da geht es dann darum, dass wir viele, viele verschiedene Daten haben. Also sie können diese Daten entweder bei Excel hochladen oder aber auch per API Schnittstelle mit unserem System.
Florian Polak: 00:05:56,720 –> 00:06:38,450
Und dann können Sie Fragen im Prinzip an diese Datenmengen stellen, um dann relevante Ergebnisse im Prinzip zu extrahieren. Mehr dazu ein bisschen später. Verschiedenste Formate funktionieren bei uns Audio Videodateien, Excel wie schon erwähnt bzw. Maschinen lesbarer Text kann angeschlossen werden. Das Ganze natürlich auch eben als Schnittstelle mit Ihrem System. Wir haben ein paar Garantien, die wir Ihnen geben. Das eine Thema ist Anti Halluzination, da komme ich gleich nachher noch kurz darauf zu sprechen, was das eigentlich ist und wie man das dagegenstellen kann, dass wir im Prinzip ihnen helfen, eigentlich, dass unsere KI die relevanten Ergebnisse aus den Textmengen oder Datenmengen auch extrahiert.
Florian Polak: 00:06:38,900 –> 00:07:17,930
Dann garantieren wir Ihnen auch, dass die Daten ausschließlich in Deutschland verarbeitet werden. Da gibt es mehrere Varianten zusammenzuarbeiten. Wir haben unsere Server grundsätzlich Berner Anbieter namens Hetzner. Das heißt, wenn Sie mit unserer Cloud zusammenarbeiten, wird das ausschließlich auf diesem Server verarbeitet. Oder wir können sogar unser gesamtes System bei Ihnen auf dem Server installieren. Haben wir bei sehr großen Kunden schon auch gemacht. Einfach damit die Daten ihr System einfach gar nicht mehr verlassen. Dann natürlich, dass die Daten von unseren Kunden ausschließlich ihnen zur Verfügung stellen. Also sowohl die Extrakte im Prinzip, die Sie mit unserer Query rausbekommen, als natürlich die Daten, die Sie bei uns hochladen.
Florian Polak: 00:07:18,170 –> 00:07:58,670
Wir nutzen Ihre Daten nicht zu Trainingszwecken, außer natürlich, das ist gewünscht. Also wir können auch im Prinzip speziell für Ihren Fall dann natürlich auch ein eigenes Datentraining durchführen. Und last but not least, wenn Sie sehr, sehr große Datenmengen haben Sie haben bei uns keine Begrenzung an hochgeladenen Daten, das heißt, Sie können da wirklich rein jagen, was auch immer Sie da drinnen haben, weil und kriegen trotzdem ein sehr performantes Ergebnis, werde ich nachher kurz noch mal ein bisschen was dazu sagen, dass Sie auch bei großen Datenmengen tatsächlich relevante Ergebnisse sehr präzise rausbekommen. Gut, dann steige ich auch schon ein mit Problemen grundsätzlich bei Studie Auswertung von Studien mittels KI.
Florian Polak: 00:07:59,570 –> 00:08:39,169
Das Hauptthema ist das Thema Halluzination. Also im Prinzip wirklich, dass die KI Ergebnisse bringt, die eigentlich nicht relevant sind. Um auf die Frage, die sie gestellt haben wir Es gibt da verschiedene Mechanismen, die man entgegenwirken kann. Ich werde nachher kurz ein bisschen was dazu sagen, was das eigentlich ist oder was üblicherweise die. Die Gründe dafür sind dann ein sehr, sehr wichtiges Ergebnis. Ich weiß nicht. Ich nehme mal an, dass viele von Ihnen schon mittlerweile mit Start up oder ähnlichen KI Systemen gearbeitet haben. Grundsätzlich gibt es geht es ja auch teilweise jetzt schon ganz gut. Allerdings sind im Regelfall gerade bei großen Datenmengen die Ergebnisse relativ ungenau oder unpräzise und eher oberflächlich.
Florian Polak: 00:08:39,590 –> 00:09:19,370
Dafür gibt es ganz gute Gründe, zu denen ich auch gleich noch ein bisschen was sagen werde. 121 anderes Thema natürlich. Je nachdem, in welchem Anbieter sie arbeiten, werden Daten teilweise zu Trainingszwecken weiterverwendet, weil die Systeme erst im Prinzip im Aufbau sind oder sich ständig weiterentwickeln. Oder die Daten werden natürlich in Anbieter an die USA weiter übermittelt. Als Beispiel wäre da zB IT zu nennen und beispielsweise das ist natürlich ein großes Risiko, weil ihre sensiblen internen Daten dann eventuell in zukünftigen Modellen im Prinzip als Antwort auch rauskommen können, was natürlich nicht in ihrem Interesse ist. Und sie haben sich auch schon ein bisschen was darüber gehört über das Thema Tokens.
Florian Polak: 00:09:19,880 –> 00:10:22,610
Und grundsätzlich trugen sie es in der Art und Weise, wie an solche Komodelle im Regelfall abrechnen oder bzw. wie. Wie viele Informationen auf einmal verarbeitet werden können. Das Man kann sich unter einem Token ungefähr ein Wort vorstellen, Das heißt, wie viele Wörter können von der KI gelesen werden? Da gibt es Limitierungen. Grundsätzlich. Zwar werden diese Kontextwindows im Prinzip also die Art, die Anzahl an Wörtern, die sie einspielen können, zwar immer größer, trotzdem haben sie da immer noch eine Limitierung, die natürlich nicht gewünscht ist. Wenn man große Datenmengen also von einer ganzen Studie beispielsweise auswerten möchte. Und eines der wichtigsten Themen für uns ist im Prinzip Nicht nur die tatsächlichen Ergebnisse der KI sollten angezeigt werden, sondern auch tatsächlich die Originalzitate, also die Originaltext stellen aus den Studien, die nämlich auch relevant sind, um vor allem den Kontext besser zu verstehen, aber auch natürlich, um zu überprüfen, ob die Antwort der KI tatsächlich richtig ist oder ob es sich beispielsweise um eine Halluzination handelt.
Florian Polak: 00:10:22,820 –> 00:11:03,950
Das sind so die wichtigsten Themen eigentlich in diesem Bereich. Ich werde mal kurz erzählen, grundsätzlich, was für Technologie sich hinter TTP versteckt. Es handelt sich um etwas, das nennt sich Large Language Model. Es sind verschiedene Arten von Modellen, aber im Prinzip basiert eigentlich alles auf dieselbe Art und Weise. Ist im Prinzip ein Modell, das gemacht wurde, um Sätze zu vervollständigen, basierend auf Wahrscheinlichkeit, das heißt, basierend auf dem Kontext, den Sie als Frage stellen, und dem Kontext, den Sie beispielsweise als Studie in das System hineinspielen. Versucht die ZBD beispielsweise die, den Satz zu vervollständigen, so dass er möglichst akkurat ist.
Florian Polak: 00:11:06,110 –> 00:11:45,920
Man muss sich darunter vorstellen Diese ganzen großen Land Language Modellen wurden mit Milliarden und Milliarden von Daten im Prinzip gefüttert. Das heißt, sie haben Milliarden von Daten im Prinzip gesehen und Sätze gelesen und können dann aufgrund dieser Trainingsdaten im Prinzip Sätze vervollständigen. Das ist im Wesentlichen eigentlich, was die Technologie hinter JPC ist. Das bedeutet natürlich, dass diese Systeme manchmal ist die wahrscheinlichste Antwort die korrekte. Das muss aber nicht immer der Fall sein. Das kann auch passieren, dass das System irgendwo abbiegt, die Frage zum Beispiel falsch versteht oder auch den falschen Kontext hat, um die Antwort im Prinzip zu generieren.
Florian Polak: 00:11:46,100 –> 00:12:25,880
Und dann passiert etwas, was im Umgangssprachlichen mittlerweile Halluzinieren genannt wird. Das ist im Prinzip ein Sammelbegriff für viele verschiedene Probleme. Das ist im Regelfall der Hauptgrund ist darauf, dass die KI im Prinzip. Auf die falschen Daten zurückgreift und dann im Prinzip die falschen Informationen liefert, um die Frage zu beantworten. Aus Nutzerperspektive ist es natürlich Sie stellen eine Frage, wollen eine Antwort haben und das System liefert Ihnen eine völlig falsche Antwort, was objektiv falsch ist und im Prinzip dann unter Halluzinieren zusammengefasst wird. Letztes Thema, was auch sehr, sehr wichtig ist, Wo ich gerade vorhin erwähnt habe, diese Kontextwindows oder auf deutsches Kontextfenster.
Florian Polak: 00:12:25,910 –> 00:13:01,730
Das ist im Prinzip schon ein bisschen ein Markttrends von den großen, laut Language Modellen sehr großen KIs, die im Moment am Markt sind. Die Idee der ganzen Sache ist, möglichst viele Daten auf einmal in das System einspielen zu können, um dadurch einen besseren Kontext für die KI zu generieren. Dadurch, dass das somit die Fragen dann besser beantwortet werden können. Die größten Modelle, die aktuell am Markt sind, sind meines Wissens nach das von Google, wo fast 1 Million solcher Tokens im Prinzip auch gleichzeitig verarbeitet werden können. Sie können da ein ganzes Buch reinschmeißen und dann im Prinzip Fragen an dieses Buch stellen.
Florian Polak: 00:13:02,720 –> 00:13:36,980
Problem bei der ganzen Sache ist, dass erstens mal ist es ein recht ineffiziente System, weil jedes Mal, wenn Sie eine Frage stellen an diese Daten, muss das gesamte Buch neu analysiert werden, was eine sehr ineffiziente Art und Weise ist. Und zwar sind diese Modelle zwar mittlerweile immer billiger, aber sie haben immer noch das Problem, dass wenn sie sehr, sehr viele Fragen stellen wollen, was bei Studien häufig vorkommt, dass ihnen dann ziemlich viel Kosten entstehen können. Und das zweite ist, was wahrscheinlich noch viel wichtiger ist Nur weil Sie einen größeren Kontext haben, heißt das nicht, dass die Antwort besser wird.
Florian Polak: 00:13:37,640 –> 00:14:14,030
Unbedingt. Zwar wird das System einen größeren Kontext haben und wird besser verstehen, um was es hier eigentlich geht. Also was hier die Studie zum Beispiel ist, heißt aber nicht, dass es eine präzise Antwort geben wird. Da komme ich ja schon zum nächsten Punkt. Warum sind denn solche KI Antworten manchmal so oberflächlich? Hintergrund der ganzen Sache ist, dass diese KIs im Prinzip darauf trainiert sind, möglichst natürlich richtige Aussagen zu treffen und keine falschen Antworten zu liefern. Eine Methode, um so was zu machen, ist im Prinzip den Kontext, die Kontextfenster zu erhöhen und mehr Daten reinzuspielen, um mehr Informationen zu zu liefern.
Florian Polak: 00:14:14,540 –> 00:14:58,820
Das Problem mit der ganzen Sache ist, dass das System darauf trainiert ist, bloß keine Fehler zu machen und bloß keine falschen Antworten zu liefern. Und aus diesem Grund im Prinzip versucht, eine Antwort zu generieren, die möglichst allgemeingültig ist und ja nicht falsch ist und in dem Kontext eben richtig ist oder und und und lieber eine oberflächliche Antwort gibt, als dass es einen tatsächlichen Fehler macht. Und das ist im Prinzip auch der Grund, warum dann im Prinzip seine Antwort relativ oberflächlich und ja allgemeingültig, aber vielleicht nicht besonders hilfreich für eine Studie ist. Was zur Folge hat das, dass diese Systeme tatsächlich in manchen Studien einfach gar nicht richtig oder gut eingesetzt werden können.
Florian Polak: 00:14:59,900 –> 00:15:41,120
Das ist so das Hauptthema. Das heißt, man muss sich ein bisschen bei diesen gängigen KI Systemen überlegen. Geht man das Risiko ein, dass das Ding halluziniert oder möchte man lieber oberflächliche Antworten haben? Und das ist im Prinzip das Hauptthema, was gerade am Markt mit diesen KI Modellen das problematisch ist. Wir gehen ein bisschen in eine andere Richtung und wir haben. Grundsätzlich werde ich ein bisschen erzählen, wie wir die Infrastruktur hinten aufgebaut haben, um genau diese beiden Probleme nicht zu haben, sondern um wirklich sehr, sehr tief reinzugehen, sehr, sehr präzise Antworten zu generieren, auch bei sehr großen Datenmengen, ohne das Problem zu haben, dass wir auf der anderen Seite Halluzinierung Stimmen haben oder die Antworten einfach sehr generisch sind.
Florian Polak: 00:15:42,980 –> 00:16:30,260
Im Prinzip Was macht unsere KI eigentlich oder was macht das System dahinter? Wir haben einen Text hier im Beispiel ist es jetzt ein Transkript. Wir haben zum Beispiel einen Audiofall von Ihnen bekommen. Das wurde von uns transkribiert. Das heißt, wir haben ein Wortprotokoll des Interviews und jetzt geht unser System über diesen Text und bricht diesen Text auf in Themenblöcke. Das heißt, es nennt sich im Fachsprache nennt sich das Ganze Junking, Das heißt im Prinzip wir wir. Ein System geht über diesen Text und schaut sich an, wo beginnt ein Thema und wo hört es wieder auf und generiert dann ebensolche solche Inhaltsblöcke und bricht diesen langen Text, der ja auch bei einer Stunde Interview mehrere 20 30 Seiten lang sein kann, in kleine Blöcke auf, die dann wiederum abgelegt werden in einem eigenen Datenbanksystem.
Florian Polak: 00:16:30,260 –> 00:17:12,619
Das Datenbanksystem nennt sich Vektor Datenbank. Es ist im Prinzip ein Datenbanksystem, das gut geeignet ist, Inhalte miteinander zu vergleichen. Das heißt, man kann sich vorstellen, ein ganzes Interview wird aufgebrochen. Man hat dann beispielsweise 1000 solche Themenblöcke und diese Themenblöcke werden dann auf dieser Datenbank als Graphen, also in einen mathematischen Wert umgewandelt und auf diese Datenbank abgelegt. Wenn Sie jetzt eine Frage haben und beispielsweise wissen wollen okay, fanden die Teilnehmer. Immer den Kunden Service gut und das System wird diese Frage wiederum analysieren. Um was geht es hier in Aufbrechen in so einen Themenblock und diesen Themenblock ebenfalls auf diese Vektordatenbank ablegen.
Florian Polak: 00:17:13,700 –> 00:17:56,060
Jetzt hat man diese zwei Themenblöcke und das System ist ganz gut geeignet zu vergleichen, Wie nah sind die aneinander dran? Das heißt, das System sucht dann auf Ihre Antwort alle relevanten Stellen in diesem Transkript raus, die geeignet sind, um Ihre Frage zu beantworten. Und diese Textblöcke werden dann genommen, werden dann eben so eine KI weitergegeben, die nicht mehr das ganze Transkript liest, sondern ausschließlich diese Themenblöcke. Daraus dann im Prinzip eine Antwort generiert und ihre Frage beantwortet hat zwei Vorteile Nummer eins Wir, die grundsätzlich. Die Antwort ist sehr, sehr präzise, weil sie im Prinzip wirklich ausschließlich den Text liest, der relevant ist, um Ihre Frage zu beantworten.
Florian Polak: 00:17:56,720 –> 00:18:30,620
Und das Zweite ist Wir können eine Rückverfolgbarkeit von Informationen garantieren. Das heißt, wir zeigen Ihnen grundsätzlich nicht nur einfach nur die Antwort der KI an, sondern wir zeigen Ihnen auch alle Textblöcke an, die relevant waren, um diese Frage zu beantworten. Und auf einmal können wir eine Rückverfolgbarkeit garantieren, was zur Folge hat, dass wir nicht nur Ihre Frage beantworten können, sondern sie das Ganze auch einfach überprüfen können. Das ist im Prinzip unser System und wir haben jetzt verschiedene Anwendungsfelder, wo wir das im Prinzip einsetzen. Erstes Thema ist beispielsweise bei diesem Kodieren von offenen Antworten in quantitativen Studien.
Florian Polak: 00:18:30,740 –> 00:19:15,890
Also beispielsweise Sie haben 1000 Antworten von Teilnehmern einer Onlinestudie, die im Prinzip einfach Informationen geben, was Sie zu dem Kundenservice gesagt haben. Jeder dieser Aussagen wird im Prinzip jetzt wiederum selbes Prinzip aufgebrochen in diese Themenblöcke. Manchmal ist so eine Antwort ja durchaus sehr, sehr lange. Dann sind es dann mehrere Themenblöcke, die werden wiederum abgelegt und die Codes, die im Prinzip genutzt werden, um das Ganze zu verdichten, werden ebenfalls als Themenblöcke abgelegt. Und dann wird eigentlich nur noch miteinander verglichen Was passt gut, welche Codes passen gut zu dieser Aussage? Und so kann man diese Ergebnisse relativ schnell verdichten, ohne die Gefahr zu gehen, dass die Ergebnisse falsch zugeordnet werden.
Florian Polak: 00:19:17,390 –> 00:19:58,070
Natürlich kann man da relativ lange Studien einfügen. Also die größten, die wir jetzt mittlerweile haben, waren glaube ich 20.000 Textnennungen, die dann im Prinzip dort nur System durch gejagt wurden. Verschiedene Datenformate unterstützen wir. Klassisch sind natürlich Excel oder SS, da dann das ganze Thema wird einfach einmal durch codiert. Das dauert im Durchschnitt für so 1000 Nennungen zirka zwei Minuten. Man kann sich die Ergebnisse natürlich wieder anschauen, kann eventuell auch nachbessern, wenn man das möchte, also einen anderen Code zum Beispiel verwenden. Oder man kann sogar dem System sagen, hier sind alle Nennungen, finden wir einen guten Code bei, nachdem ich das Ganze verdichten kann drüben.
Florian Polak: 00:19:58,520 –> 00:20:45,780
Und das Ganze im Prinzip dann durch Codieren lassen. Und die Formate können dann wieder als Excel oder SSDatei wieder exportiert werden. Das nächste Thema ist eher in der qualitativen Forschung. Hmmm. In der qualitativen Forschung geht es mir darum, Interviews oder Gruppendiskussionen tatsächlich zuerst einmal in Text zu transkribieren. Da haben wir Verschiedenes, verschiedenste Spracherkennungsalgorithmen für die verschiedenen Sprachen. Im Regelfall können wir alle romanischen Sprachen gut abdecken. Wir können vor allem im Deutschen, wo unser Fokus liegt, auch die verschiedenen Dialekte und Akzente auch ganz gut im Prinzip kennen. Je nach Aufnahmebedingungen schaffen wir da im Durchschnitt circa 95 % Genauigkeit.
Florian Polak: 00:20:45,780 –> 00:21:34,050
Das entspricht einer geschulten Transkriptionspersonen, die im Prinzip daneben sitzt und jedes Wort mitprotokolliert. Dann haben Sie mal den. Das Wortprotokoll, also im Prinzip das Transkript des Interviews oder der Gruppendiskussion. Und wenn es sich um eine Gruppendiskussion handelt, kann zum Beispiel dann automatisch auch das Gespräch nach Sprechern aufgebrochen werden. Das heißt, wenn Sie beispielsweise fünf Leute zu einem Thema befragen, wird dann schon aufgebrochen nach Sprecher, ein Sprecher, zwei Sprecher, drei Sprecher vier und fünf natürlich. Und sie können nachher dann wiederum, weil das System das Ganze dann aufbricht, wiederum sich aussuchen. Okay, möchte ich eine Analyse über alle Teilnehmer machen oder möchte ich wirklich tatsächlich einfach für jeden Sprecher relevante Informationen rausziehen?
Florian Polak: 00:21:35,250 –> 00:22:16,650
Und das System gibt Ihnen dann im Prinzip die Antworten auf Ihre Fragen. Das kann zum Beispiel der Leitfaden sein, den Sie hinterlegen oder auch Ihre Research fragen, um spezifisch nach bestimmten Informationen zu suchen. Das Spannende der Sache ist Sie können ein Interview hochladen und das analysieren. Oder Sie können ein ganzes Studio hochladen, um viele verschiedene Informationen aus den beispielsweise zehn Interviews rauszuziehen, um dann gemeinschaftlich einfach sich ein Bild zu machen über diese verschiedenen qualitativen Studien, die Sie da durchgeführt haben. Und der letzte Punkt ist wirklich tatsächlich, dass wir unser neuestes Modul eigentlich, dass wir tatsächlich große Mengen an Daten im Prinzip anbinden können.
Florian Polak: 00:22:16,650 –> 00:23:03,240
Ein klassisches Beispiel wären zum Beispiel Social Media Kanäle, die Sie per API Schnittstelle zum Beispiel anschließen können, um dagegen dann Fragen zu stellen. Sprich da werden Datenpunkte im Prinzip von Ihnen in unser System eingespielt, maschinenlesbar. Der Text muss das Ganze sein und dann können Sie tatsächlich Ihre Fragen gegen diese Datensätze stellen. Das können Exceldateien sein, das können Textdateien sein, über eine API zum Beispiel. Das können aber auch Transkripte von Interviews natürlich sein, um dann wirklich eine gesamt einheitliche Auswertung über diesen diese ganze Studie zu machen. Wunderbar geeignet natürlich für andere Communities, wo es grundsätzlich relativ viele Daten gibt, wo auch über mehrere Tage oder Wochen hinaus gewisse Informationen gesammelt werden von Usern, um dann wirklich so eine Auswertung tatsächlich zu machen.
Florian Polak: 00:23:03,870 –> 00:23:55,080
Das System zeigt ihnen dann immer die Antwort an, aber auch die Referenzen wirklich von den jeweiligen Textblöcken wiederum woher die Informationen eigentlich kommen, sodass sie dann leicht eine Möglichkeit haben, das Ganze zu überprüfen. Genau. Als Epischnittstelle können Sie das natürlich anschließen. Ähm, grundsätzlich wie funktioniert unser System? Gibt grundsätzlich mal zwei Möglichkeiten, wieder zusammenzuarbeiten. Wir können das Ganze bei Ihnen auf dem Server installieren. Das wäre dann so eine On Premise Installation. Das heißt, dann wird das Ganze wirklich auf Ihren Server betrieben. Keine Daten verlassen Ihr Unternehmensnetzwerk. Der einzige Nachteil, den Sie da haben, abgesehen davon, dass es ein bisschen umständlich ist, ist, dass Sie da relativ starke Server brauchen, inklusive solche Grafikkarten, also GPUs genannt, die geeignet sind, im Prinzip, um diese Systeme sehr performant laufen zu lassen.
Florian Polak: 00:23:55,470 –> 00:24:39,750
Oder sie entschließen sich, das Ganze auch mit uns zusammenzuarbeiten in der Cloud. Da garantieren wir Ihnen wie gesagt, dass die Daten ausschließlich in Deutschland verarbeitet werden. Das ist dann im Prinzip auf unserem Server, der in Nürnberg steht. Serveranbieter ist ein deutsches Unternehmen namens Hetzner und wo im Prinzip dann die Daten analysieren zu lassen. Ähm, grundsätzlich natürlich sind diese Systeme hinreichend gesichert, sprich wir verarbeiten ihre Daten auch wirklich nur so, wie sie das Ganze von uns wünschen. Gibt da verschiedene Möglichkeiten, wie wir zusammenarbeiten können. Man kann auch eigene Datentrainings für sie machen, wenn sie das wünschen. Und es gibt natürlich auch die Möglichkeit in anderen EU Ländern beispielsweise einen Cloudserver aufzubauen, was wir grundsätzlich auch schon in der Vergangenheit gemacht haben.
Florian Polak: 00:24:41,390 –> 00:25:18,530
Zu den Preisen gibt es zwei verschiedene Art und Weise, mit uns zusammenzuarbeiten. Das eine Thema wäre wirklich so einer on demand. Das heißt wirklich, Sie haben ein Projekt, Sie kommen auf uns zu und sagen, wir wollen jetzt dieses Projekt mit ihnen durchführen. Wir machen ein Angebot und rechnen dann nach der Studie im Prinzip ab. Da rechnen wir grundsätzlich immer nach Datensätzen ab, also im Prinzip, wenn es sich um qualitative Interviews handelt. Das rechnen wir meistens über Audiostunden ab. Wenn es sich um Excel Dateien handelt, die abgerechnet werden müssen, haben Sie, zahlen Sie einen Cent pro Betrag für eine Pro Excel Zelle, also pro Nennung des Befragten und rechnen das Ganze völlig flexibel ab.
Florian Polak: 00:25:18,530 –> 00:25:54,140
Keine Bindung, oder? Wir haben auch natürlich das Corporate Offer. Das machen wir bei größeren Kunden mit uns, dass sie einen jährlichen Fixpreis haben, dann haben sie keine Mengeneinschränkung, können das Ganze mit uns machen nach Lust und Laune und können auch bauen das Ganze für sie im Prinzip dadrauf. Das kann natürlich auch alles kombiniert werden. Das heißt, es gibt natürlich auch die Möglichkeit, dass man zum Beispiel eine qualitative Studie durchführt, die Ergebnisse dann verdichtet. Im Prinzip. Beispielsweise im Quantenmodul, dass man dann wirklich das Ganze auf wirkliche Wortnennungen verdichtet und das Ganze kodiert, um dann eine sehr, sehr gute Auswertung zu kriegen.
Florian Polak: 00:25:54,140 –> 00:26:31,070
Und um sich einen Report im Prinzip schnell herzurichten. Das wäre auch schon alles von meinem Webinar. Jetzt würde ich ganz kurz auf die Fragen eingehen, die Sie grundsätzlich hier im Chat gestellt haben. So gibt es die Möglichkeit, Audiodateien zu testen zu lassen. Starke Dialekt aus Österreich zum Beispiel. Ja, grundsätzlich. Sie können das bei uns auch immer alles testen. Das heißt da einfach uns gerne unverbindlich einfach schreiben. Wir bieten natürlich immer die Möglichkeit an, das Ganze auszuprobieren, sei das jetzt eben bei Audiodateien mit Akzenten zum Beispiel, aber auch natürlich bei Excel Studien, dass Sie das mal ausprobieren können und sich von der Qualität überzeugen.
Florian Polak: 00:26:31,880 –> 00:27:11,870
Bei den Akzenten Grundsätzlich gilt je in Österreich vor allem je weiter östlich, desto leichter, je weiter westlich, desto schwieriger. Schweizer Akzente und Dialekte sind tatsächlich ein bisschen problematisch, weil es keine keine einheitliche Art gibt, wie man Schweizerdeutsch schreibt. Deswegen gibt es auch wenig Möglichkeiten, da leicht einen Spracherkennungsalgorithmus aufzubauen. Wir haben aber schon die verschiedensten Projekte auch in Österreich gemacht. Sprich einfach kontaktieren und einfach ausprobieren, würde ich vorschlagen. Dann die nächste Frage war dann auch noch Können auch Transkripte von Face to Face Gruppendiskussionen mit Zuordnung der sprechenden Person gemacht werden oder nur von anderen Gruppen? Face to face geht auch.
Florian Polak: 00:27:11,870 –> 00:27:53,330
Wir brauchen grundsätzlich eine Aufnahme in einer Art oder oder der anderen. Also beispielsweise, wenn Sie wirklich eine Face to Face Studie haben und das Ganze aufnehmen, können Sie nachher die Audiodateien nehmen, hochspielen und das Ganze dann im Prinzip transkribieren lassen. Wir wir machen das nicht über die verschiedenen Kanäle, also beispielsweise bei einem Online Meetings über Teams gibt es ja die verschiedenen Sprecherkanäle und im Regelfall hat man bei der Transkription dann so eine Aufteilung nach den verschiedenen Kanälen. Wir machen das Ganze über eine eigene Sprechererkennung, das heißt, wir haben da einen eigenen Algorithmus drinnen, der die Unterschiede in den Stimmlagen erkennt und das Gespräch danach im Prinzip auf aufbricht, quasi.
Florian Polak: 00:27:54,260 –> 00:28:28,400
Bedeutet aber natürlich auch, dass das wir nicht wissen, dass ich zum Beispiel der Florian Pollack bin, sondern wir wissen eigentlich dann auch nur okay. Es gab fünf Sprecher in diesem Gespräch und folgender Sprechereinsatz folgende Sachen gesagt natürlich, wenn man nachher die Informationen wieder braucht, um eine Analyse zu fahren, beispielsweise, dass man die Analyse machen möchte, über was die weiblichen Teilnehmer der Studie gesagt haben, dann kann man diese Referenzen wieder einfügen. Das müsste dann manuell im Nachhinein gemacht werden von Ihnen, geht aber recht schnell, um dann nachher im Prinzip in der Auswertung auf der Ebene auch noch machen zu können.
Florian Polak: 00:28:29,840 –> 00:29:11,360
Haben Sie auch Familien mit Schweizer deutschen Dialekten? Ja, haben wir. Schweizerdeutsche Dialekte sind leider etwas schwierig, muss ich noch dazu sagen. Wir haben mittlerweile ein neues Modell, das glaub ich nächste Woche rauskommt, das tatsächlich für Schweizerdeutsch Ergebnisse bringt, die, sagen wir mal deutlich besser sind als das, was sie bisher am Markt kennen. Wir müssten dann allerdings auch ausprobieren, wie die wie die Qualität wirklich ist, weil das eben ein sehr, sehr neues Modell ist. Grundsätzlich ist das ein bisschen schwieriger natürlich als österreichisch oder oder deutsch Deutsch mit den verschiedenen Dialekten und Akzenten dort. Und dann kann man von Ihnen anonymisierte, pseudonymisierte Beispiele für eine Textauswertung erhalten, um ein Gefühl für die Ergebnistypen zu bekommen.
Florian Polak: 00:29:11,360 –> 00:29:52,440
Ja, können Sie, wenn Sie grundsätzlich mit uns machen. Meistens dann so eine Demo. Da haben wir auch eine Demostudie drinnen, wo Sie das Ganze sich einmal anschauen können und durchaus dann im Prinzip das Ganze auch verwenden können, um selber sich zu überprüfen, ob das System passt oder nicht. Dann kann die ja vorher die Webseite oder Dokumente crawlen und Spezialbegriffe Spezialabkürzungen zu identifizieren. Wir haben viele Fachbegriffe, die auch von Kunden verwendet werden. Grundsätzlich. Das Thema Spezialbegriffe ist immer wieder relevant. Für qualitative Studien ist es insbesondere dann relevant, weil die Spracherkennung basiert nämlich auch auf dem üblichen Sprachgebrauch.
Florian Polak: 00:29:52,860 –> 00:30:42,570
Wenn es dann Spezialbegriffe gibt, Eigennamen, Firmennamen beispielsweise. Sowas kann im Regelfall sehr, sehr einfach im Prinzip hochgeladen werden, in dem sie eigentlich ein Level hochladen, Ob wir es von der Webseite crawlen. Grundsätzlich einen Service. Wir haben theoretisch Crawler mit so was zu machen. Effizienter wäre es wahrscheinlich, wenn wir einfach im Prinzip sie uns die Webseite sagen. Wir schauen uns das Ganze für Sie an, erstellen wir eine Excelliste an diesen Fachbegriffen und laden die einmal hoch. Das dauert im Regelfall zwei drei Minuten, ist recht schnell gemacht und dann werden die Begriffe auch richtig erkannt. Üblicherweise, wenn es sich um Webbegriffe handelt, die auf Webseiten sind, macht es in der Textauswertung gar nicht mal so groß eine Rolle, weil die KI Systeme im Regelfall mit sehr, sehr großen Datenmengen gefüttert wurden, sodass auch Spezialbegriffe dann auch richtig erkannt werden.
Florian Polak: 00:30:42,570 –> 00:31:26,060
Also ein Kontext passt dann im Regelfall ganz gut. Insofern sollte das damit auch eher kein Problem sein. Und welche Sprachen können Sie abbilden? Alle europäischen und auch nichteuropäischen Sprachen. Grundsätzlich also was auf jeden Fall sehr, sehr gut funktioniert, sind die romanischen Sprachen, also Deutsch, Englisch, Französisch, Spanisch, Italienisch. Wir hatten dann aber auch Niederländisch, Dänisch, die auch gut funktioniert haben. Im Englischen natürlich die verschiedenen Sprachgruppen, die wir haben. Also wir hatten tatsächlich auch eine Studie, die mit singapurianischen Akzenten waren, wo ich in der Spracherkennung, also ich persönlich hätte weniger verstanden als unsere KI da tatsächlich. Also da gibt es auch die verschiedensten Möglichkeiten.
Florian Polak: 00:31:26,070 –> 00:31:56,130
Wir haben aber auch die Möglichkeit, wenn es, sagen wir mal, eine sehr exotische Sprache ist, die nicht sehr häufig vorkommt, hier noch mit anderen Anbietern zusammenzuarbeiten. Dann müssten wir uns aber im konkreten Fall anschauen, was sie da brauchen. Und auch da müssen wir uns genau noch mal erkundigen, wie das Ganze funktioniert, dass wir auch garantieren können, dass die Daten ausschließlich auf unserem Server verarbeitet werden, weil das dann halt eine Spracherkennung ist, die wir nicht anbieten, da gerne einfach auf uns zutreten. Wir können dann im Spezialfall gerne noch mal drüber reden, wenn wir schon beim Thema Sprache sind.
Florian Polak: 00:31:56,160 –> 00:32:42,570
Ein wichtiger Punkt geht auch Beispiel insbesondere bei qualitativen Studien. Sie können auch im Prinzip, wenn Sie einen Leitfaden beispielsweise auf Deutsch haben und die Studien mehrsprachig sind, also beispielsweise auf Englisch und auf Deutsch, dann können Sie das Ganze transkribieren lassen, auf Englisch und jeweils auf Deutsch und dann aber den Leitfaden nehmen, um den auch auf die englischen Transkripte gegen die zu stellen, sodass die Antworten aus dem Kontext, aus dem englischen Transkript raus extrahiert werden, um dann im Prinzip aber auf Deutsch übersetzt werden. Das funktioniert. Es ist genaugenommen kein Übersetzungsprogramm, sondern es ist, dass die KI versteht den Kontext der anderen Sprache, weil die Trainingsdaten in sowohl auf Englisch als auch auf Deutsch zur Verfügung waren.
Florian Polak: 00:32:42,840 –> 00:33:17,060
Das funktioniert erstaunlich gut. Das heißt, Sie können auch mehrsprachige Studien mit uns durchführen, ohne weitere Probleme. So, dann die nächste Frage Können mehrere Sprachen gleichzeitig verboten werden? Ja, das war kurz die Frage, die ich gerade beantwortet haben. Also zum Beispiel für Studien in Belgien. Ja, das geht grundsätzlich. Also wenn Sie eine französischsprachige Studie haben und das andere wäre Flämisch, zum Beispiel, sollte das kein Problem sein, müssten wir das einmal transkribieren in die jeweilige Sprache. Und wenn Sie dann Ihren Leitfaden aus auf beispielsweise Deutsch haben, werden die Antworten im Prinzip genutzt, um dann ein Ergebnis zu produzieren.
Florian Polak: 00:33:17,070 –> 00:34:08,850
Also Ihre Antwort zu der Frage zu beantworten. Wenn Sie denn die Zitate haben wollen, sind die dann logischerweise aber in der Originalsprache. Und die letzte Frage Können bei quantitativen Studien demografische Daten mit offenen Ländern verknüpft werden dann die Texte danach analysiert, also zum Beispiel bei Männern ist es so und bei Frauen ist es so, Ja, das geht also grundsätzlich. Das wäre dann am ehesten unser letztes Modul, von dem ich gesprochen habe, dieses hier, dass Sie dann eine ganze Excel hochladen, wo dann die ganzen relevanten Datenpunkte drinnen sind und sie dann dagegen einfach die Fragen stellen. Also da können Sie dann auch eine Auswertung machen nach Geschlechtern, nach Informationen, die grundsätzlich in diesen Exceldateien drin sind, um relevante Ergebnisse zu machen, kann natürlich auch kombiniert werden mit den anderen Modulen, die wir haben, um dann so ein Excel zu produzieren, gegen das Sie dann im Prinzip Ihre Research Fragen stellen können.
Florian Polak: 00:34:10,320 –> 00:34:46,139
Okay, wunderbar. Dann waren das, glaube ich, alle Fragen. Hatte es noch eine Frage? Können Sie die Preise der Pakete bitte noch mal wiederholen? Wir haben. Jetzt kommt ein bisschen darauf an, in welcher Kombination Sie das Ganze machen wollen. Bei den Preisen gilt es grundsätzlich zwei Varianten zusammenzuarbeiten Entweder Abrechnung nach Projekten. Das heißt, Sie haben beispielsweise zehn Interviews, die Sie mit uns transkribieren und dann auswerten wollen und wir machen. Ich gebe Ihnen einen Preis, nachdem Sie das Ganze auswerten können und sie zahlen dann nach Durchführung des Projektes. Oder die Variante ist, dass Sie einen Pauschalpreis mit uns machen.
Florian Polak: 00:34:46,139 –> 00:35:17,370
Da kommt es wie gesagt darauf an, welche Funktionen Sie gerne haben wollen. Und dann machen wir einen Pauschalpreis pro Jahr. Und dann ist es uns auch egal, wie viele Studien Sie darüber laufen lassen. Kommt darauf an, in welchem Kontext Sie machen. Das Corporate aber macht im Regelfall dann Sinn, wenn Sie viele Datenmengen haben oder sehr, sehr viele Studien durchführen. Ansonsten würde ich Ihnen wahrscheinlich dazu raten, das Ganze auf Projektbasis Minus zu machen. Gut, dann vielen Dank, dass Sie heute ins Webinar gekommen sind. Wenn Sie grundsätzlich noch Fragen haben Sie können. Meine Emailadresse finden Sie hier unten.
Florian Polak: 00:35:17,820 –> 00:35:38,190
Sie können uns jederzeit natürlich auch schreiben. Grundsätzlich werden wir auch, glaube ich, eine Zusammenfassung von diesem Webinar auch nochmal zirkulieren. Die Zusammenfassung ist dann auch schnell generiert für unsere Studie. Dann haben Sie da auch schon mal einen Überblick, wie gut das System eigentlich erarbeitet und habe mich sehr gefreut, dass Sie heute gekommen sind. Und ich wünsche Ihnen noch einen schönen Nachmittag. Vielen Dank!
A Comprehensive Overview of Webinar Topics
The webinar provided attendees with a structured exploration of AI's role in market research, covering the following topics:
- The fundamentals of AI systems and their application in market research.
- Strategies for overcoming common AI integration challenges, with a focus on Tucan.ai's unique methodologies.
- An in-depth look at Tucan.ai's product suite, featuring case studies that demonstrate their problem-solving capabilities in real-world scenarios.
- The critical importance of data security in AI applications and Tucan.ai's unwavering commitment to client data protection.
Key Insights and Discussion Points
A highlight of the webinar was Florian Polak's explanation of "AI hallucinations." He used the analogy of a librarian to describe Tucan.ai's data chunking and vector databases, which ensure that the AI, like a skilled librarian, can efficiently sort through vast amounts of information to find the exact insights needed without distraction.
Practical Tips for Market Research Professionals
The webinar provided actionable advice, including:
- Implementing Tucan.ai's anti-hallucination features to validate AI-generated insights, with Polak emphasizing, "Accuracy is the cornerstone of our AI solutions."
- Applying AI for rapid coding of open-ended survey responses, transforming hours of manual work into a task that takes mere minutes.
- Utilizing Tucan.ai's multilingual capabilities to analyze diverse data sets, enabling comprehensive and inclusive research studies.
The AI Advantage
By addressing the specific challenges of market researchers with state-of-the-art AI solutions, market researchers not only can streamline their research process but also ensures more reliable and actionable insights. Whether it's for niche studies or a large-scale projects, AI tools can be tailored to meet the unique requirements of each research initiative.
Increase your productivity tenfold!
Case Study: Cutting Qualitative Data Analysis Time from 2 Weeks to 1 day
Download the case study for free!
Discover how Tucan.ai optimized the processing of qualitative studies in a market research company and drastically increased their efficiency and accuracy.






Key Results
This case study demonstrates the effective use of AI to improve market research, with significant advances in analysis time and data quality:
- Efficient analysis: Reducing the analysis time of qualitative studies from 14 working days to 10 hours improves agility in market research.
- Enhanced accuracy: With an accuracy rate of 97%, Tucan.ai's innovative chunking technology contributes to reliable and precise results.
- Optimized processes: Adaptation of the system to specific company requirements leads to increased efficiency, reduces manual work and thus cuts operating costs.
These advances not only support faster decision-making, but also contribute to the increased competitiveness of the market research company.
Download the case study for free!
We advise you on your use case!
Case Study: AI-Automated Contract Analysis with 98% accuracy
Download the case study for free!
Discover how one law firm transformed its contract analysis processes by implementing Tucan.ai's system:





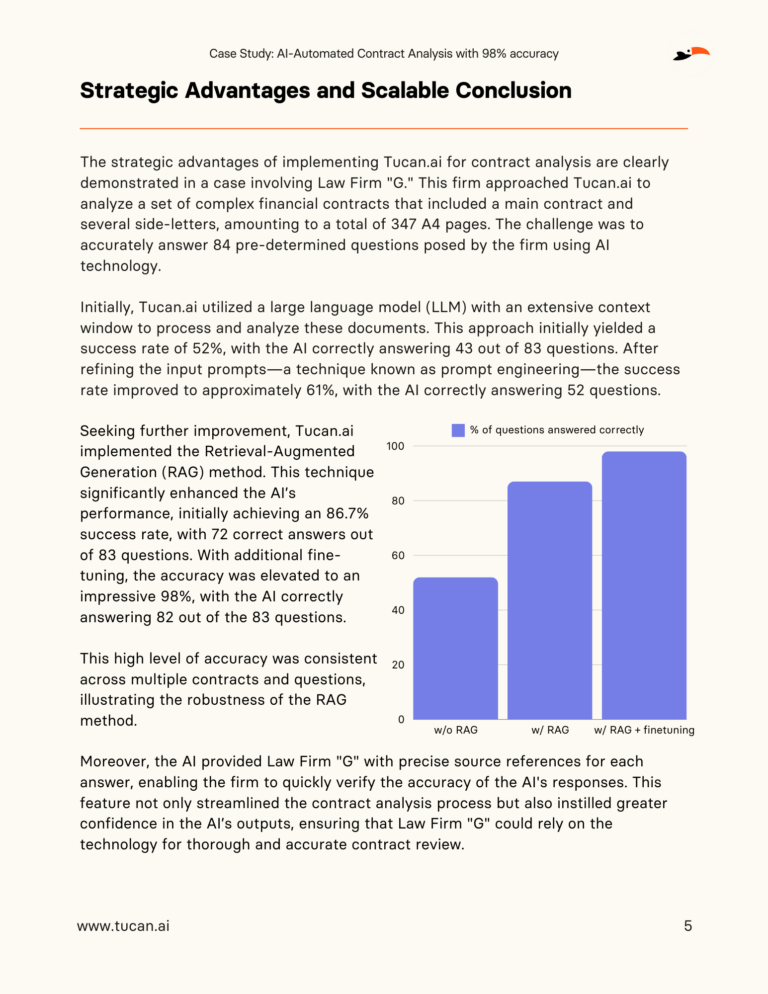

Key Results
This case study shows how the use of AI technology not only significantly increases efficiency in contract analysis, but also improves legal accuracy and shortens processing times:
- Dramatic acceleration: Reduce analysis time for complex contracts to just one hour.
- High accuracy: Thanks to the innovative chunking technique, the AI achieved an analysis accuracy of 98%, which strengthens confidence in the legal processes.
- Strategic improvements: Scalable results through the implementation of the RAG AI system, with consistency across multiple contracts and results with accurate source citations.
These innovations have not only simplified contract analysis, but have also strengthened the firm's strategic performance.
Download the case study for free!
We advise you on your use case!
Case Study: Enhancing Customer Service Efficiency by 76% in 6 months
Download the case study for free!
Discover how an insurance company transformed their customer service operations by implementing Tucan.ai's AI system:







Key Results
This case study shows how strategic planning in the application of AI not only increases customer satisfaction, but also future-proofs an important line of business:
- Increased efficiency: Automation rate of 76% for e-mail inquiries and reduction of response times from 3.5 days to just 4 hours.
- Increased accuracy: Using proprietary "chunking" technology, the AI achieved 98% response accuracy, resulting in a significant increase in customer satisfaction.
- Cost reduction: Significant reduction in operating costs by reducing dependence on manual labor.
- Positive feedback: Improved work processes and greater job satisfaction among customer service employees.
Download the case study for free!
We advise you on your use case!
Case Study: Steigerung der Effizienz des Kundendienstes um 76% in 6 Monaten
Laden Sie die Case Study kostenlos herunter!
Entdecken Sie, wie eine Versicherungsgesellschaft durch die Implementierung des KI-Systems von Tucan.ai den Kundenservice revolutioniert hat:







Die wichtigsten Ergebnisse
Diese Fallstudie zeigt, wie strategische Planung in der Anwendung von KI nicht nur die Kundenzufriedenheit steigert, sondern einen wichtigen Geschäftszweig zukunftssicher macht:
- Effizienzsteigerung: Automatisierungsrate von 76% bei E-Mail-Anfragen und Reduzierung der Antwortzeiten von 3,5 Tagen auf nur 4 Stunden.
- Erhöhte Genauigkeit: Durch die proprietäre "Chunking"-Technik erreichte die KI eine Antwortgenauigkeit von 98%, was zu einer erheblichen Steigerung der Kundenzufriedenheit führte.
- Kostensenkung: Deutliche Reduzierung der Betriebskosten durch Verringerung der Abhängigkeit von manueller Arbeit.
- Positive Rückmeldungen: Verbesserte Arbeitsabläufe und höhere Arbeitszufriedenheit bei den Kundendienstmitarbeitern.
Laden Sie die Case Study kostenlos herunter!
Wir beraten Sie zu Ihrem Use-Case!
KI für Vertragsanalysen und Recherchearbeiten: was Sie beachten müssen.
Laden Sie das Whitepaper kostenlos herunter!
Künstlichen Intelligenz (KI) hat in verschiedenen Branchen eine neue Ära der Effizienz und Effektivität eingeläutet, wobei der Rechtsbereich keine Ausnahme bildet. Da die Komplexität von Rechtsfällen mit dem exponentiellen Wachstum von Daten zunimmt, erscheint KI als Hoffnungsträger für die Rationalisierung von Abläufen, die Senkung von Kosten und die Verbesserung der Genauigkeit und Qualität der juristischen Arbeit. Die Integration von KI in rechtliche Zusammenhänge ist jedoch nicht frei von Herausforderungen. In unserem Whitepaper "KI für Vertragsanalysen und Recherchearbeiten: was Sie beachten müssen." gehen wir genau auf diese Fragen ein und bieten Juristen einen leicht verständlichen Leitfaden zu den neuesten KI-Technologien, die für juristische Anwendungen geeignet sind.











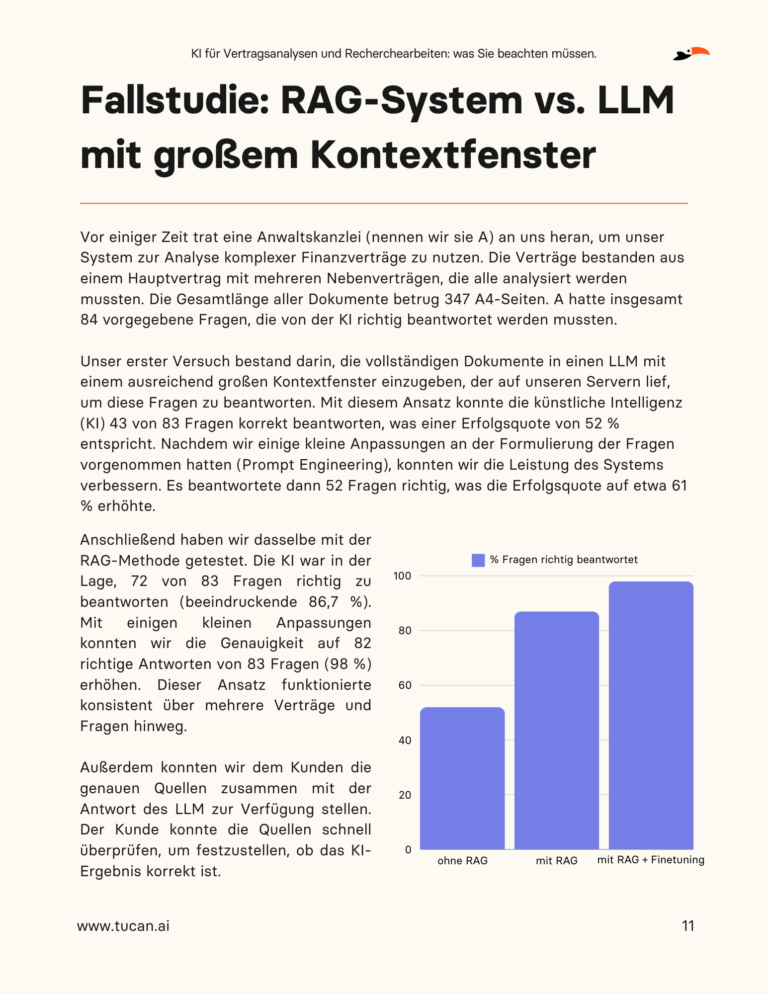





Zentrale Herausforderungen bei der Einführung von KI in der Rechtsbranche
In der Rechtsbranche ist der Einsatz von KI, insbesondere von Large Language Models (LLMs), zwar transformativ, steht aber vor erheblichen Herausforderungen, die eine nahtlose Integration erschweren. Das Problem der "Halluzinationen", bei denen KI überzeugende, aber ungenaue Antworten liefert, hat zu ernsthaften Konsequenzen geführt, wie z. B. Geldstrafen, die Anwälten auferlegt wurden, weil sie ChatGPT für fiktive juristische Recherchen eingesetzt haben. Außerdem steht die Undurchsichtigkeit der KI-Entscheidungsfindung, die als "Black Box" bezeichnet wird, im Widerspruch zu den Forderungen des Rechtssektors nach Transparenz und Zuverlässigkeit. Die Schwierigkeiten der KI, komplexe menschliche Anfragen zu verstehen, und die Abhängigkeit von Prompt-Engineering unterstreichen die Grenzen ihres kontextuellen Verständnisses. Die strengen Anforderungen der Branche an den Datenschutz und die Sicherheit erschweren die Nutzung von Cloud-basierten KI-Lösungen zusätzlich. Schließlich wirft der sich entwickelnde Charakter von KI-Modellen Fragen der Zuverlässigkeit und Konsistenz auf, da die Antworten auf identische Anfragen im Laufe der Zeit variieren können. Diese Herausforderungen unterstreichen die Notwendigkeit eines sorgfältigen und fundierten Ansatzes für die Nutzung von KI in der Rechtspraxis.
Laden Sie das Whitepaper kostenlos herunter!
Innovationen und Lösungen
In dem Bestreben, die Anwendung von KI im juristischen Bereich voranzutreiben, sind bemerkenswerte Innovationen und Lösungen entstanden. Die Einführung von Retrieval Augmented Generation (RAG)-Systemen stellt einen entscheidenden Fortschritt dar, da sie eine Methode bieten, um präzise und genaue Antworten zu liefern, indem sie umfangreiche Texte in überschaubare Segmente zerlegen. Dies erhöht nicht nur die Genauigkeit der Ergebnisse, sondern trägt auch Bedenken hinsichtlich des Datenschutzes Rechnung, indem es den Betrieb von KI auf privaten Servern erleichtert. Darüber hinaus hat die Entwicklung neuartiger Chunking-Techniken, bei denen Texte auf der Grundlage des Kontexts und nicht anhand fester Parameter segmentiert werden, die Fähigkeit der KI zur Analyse von Rechtsdokumenten erheblich verbessert. Zudem stellt die Automatisierung des Prompt-Engineering eine bahnbrechende Lösung für die Herausforderungen der Eingabegenauigkeit dar. Durch die Entwicklung von Systemen, die reguläre juristische Anfragen automatisch in KI-verständliche Formate übersetzen, kann die ursprüngliche Absicht der Fragen deutlich besser gewahrt und die Präzision der Ergebnisse erhöht werden. Zusammen versprechen diese Innovationen eine effektivere und sicherere Integration von KI in der Rechtsbranche und eröffnen neue Wege für ihre Anwendung.
Um sich in der komplexen Landschaft der KI in der Rechtsbranche zurechtzufinden, ist es von entscheidender Bedeutung, ihre Vorteile und Fallstricke zu verstehen. Unser Whitepaper ist ein Guide für Juristen, die KI durchdacht und erfolgreich in ihre Praxis integrieren wollen.
Laden Sie das Whitepaper kostenlos herunter!
Wir beraten Sie zu Ihrem Use-Case!

What you need to consider when using AI for contract analysis and research work
Download the whitepaper for free!
The advent of Artificial Intelligence (AI) has ushered in a new era of efficiency and effectiveness in various industries, with the legal field being no exception. As the complexity of legal cases increases alongside the exponential growth of data, AI appears as a beacon of hope for streamlining operations, cutting costs, and enhancing the accuracy and quality of legal work. However, the integration of AI in legal contexts is not devoid of challenges. In our whitepaper, "What you need to consider when using AI for contract analysis and research work," we dive into these very issues, providing legal professionals with a digestible guide to the latest AI technologies apt for legal applications.











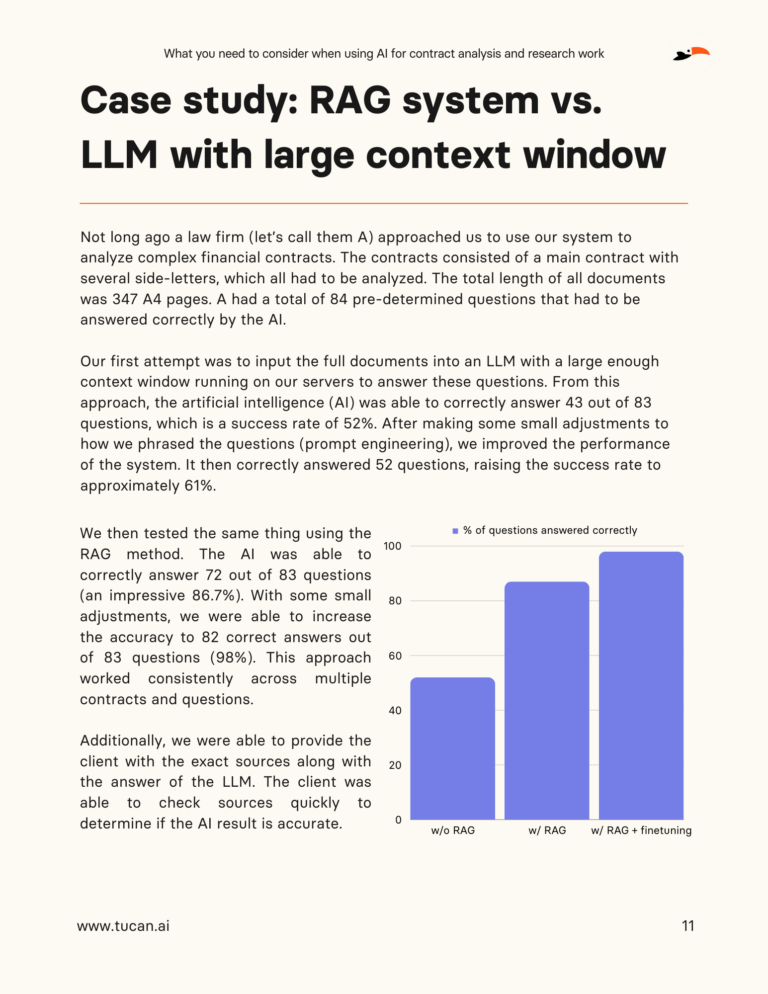





Core Challenges in AI Adoption for the Legal Industry
In the legal industry, the adoption of AI, particularly Large Language Models (LLMs), while transformative, faces significant challenges that hinder its seamless integration. The problem of "hallucinations," where AI produces convincing yet inaccurate answers, has led to serious repercussions, such as fines imposed on lawyers for utilizing ChatGPT for fictitious legal research. Moreover, the opaque nature of AI's decision-making, termed the "black box" issue, clashes with the legal sector's demand for transparency and reliability. Additionally, AI's struggle to comprehend complex human queries and the dependency on prompt engineering underscore its limitations in contextual understanding. The industry's stringent requirements for data privacy and security further complicate the utilization of cloud-based AI solutions. Finally, the evolving nature of AI models introduces issues of reliability and consistency, as responses to identical queries may vary over time. Together, these challenges underscore the critical need for a cautious and informed approach to leveraging AI in legal practices.
Download the whitepaper for free!
Innovations and Solutions
In the quest for advancing AI's application in the legal sector, notable innovations and solutions are emerging. The introduction of Retrieval Augmented Generation (RAG) systems marks a pivotal advancement, offering a method to deliver precise and accurate answers by breaking down extensive texts into manageable segments. This not only bolsters the accuracy of results but also addresses data privacy concerns by facilitating AI's operation on private servers. Furthermore, the development of novel chunking techniques, which segments texts based on context rather than fixed parameters, significantly enhances AI's capability in analyzing legal documents. Additionally, the automation of prompt engineering represents a breakthrough solution to the challenges of input precision. By developing systems that automatically translate regular legal queries into AI-comprehensible formats, there's a marked improvement in preserving the original intent of questions and enhancing the precision of outcomes. Together, these innovations promise a more effective and secure integration of AI in the legal industry, opening new avenues for its application.
In navigating the complex landscape of AI in the legal industry, understanding its benefits and pitfalls is paramount. Tucan's whitepaper serves as an essential compendium for legal professionals seeking to integrate AI into their practice thoughtfully and successfully.
Download the whitepaper for free!
We advise you on your industry use-case!
Strategies for analyzing huge amounts of text with AI: the use of chunking and vector databases
Table of contents
In the age of digital transformation, large language models (LLMs) are opening up new ways of analyzing huge volumes of text stored in databases. These advanced AI systems deliver on the promise of gaining deep insights and competitive advantages from the wealth of data. However, they reach their limits due to the so-called token limitation, a technical restriction on the amount of data that can be processed. This becomes a particularly challenging hurdle when trying to analyze millions of text documents in depth or gain new insights:
Suppose a company wants to analyze 1,000,000 text documents. If special methods are not used, it faces major problems: Due to token limitation, an LLM can only analyze parts of the documents per run, which leads to a loss of information. Without a breakdown into manageable units and without a semantically intelligent database, there is a considerable loss of context. Documents have to be viewed in isolation, which makes it difficult to gain deeper insights. The analysis is also extremely time-consuming and resource-intensive, as each document has to be processed in full individually.
Chunking & vector data: easily analyze 1,000,000+ documents
An effective method of circumventing this limitation is the combination of smart chunking and the use of vector databases. By breaking down complex texts into smaller sections that can be handled by LLMs (chunking), it is possible to analyze large volumes of data without the restrictions imposed by token limits. In addition, vector databases make it much easier to access and analyze relevant information thanks to their ability to process and query semantic vector representations quickly and efficiently. This combination significantly increases the processing capacity and precision of LLMs and opens up the possibility of using the full power of the technology to gain valuable insights from the flood of data.
Download AI knowledge management one-pager
When analyzing large amounts of data, such as 1,000,000 text documents, the analysis process changes significantly:
- Efficient data processing:Splitting documents into smaller units (chunking) makes them easier for LLMs to process, as token limitations are bypassed.
- Advanced contextualization: Vector databases enable a deeper context analysis by quickly assigning semantically similar text parts. This significantly improves the understanding and classification of information.
- Time efficiency and scalability: The documents are broken down into smaller parts and information is retrieved efficiently using vector databases. This significantly speeds up processing, optimizes analysis and saves resources.

Real-world examples
Example for the legal department of a private equity fund
A private equity fund uses LLMs to check the compliance of its extensive and transnational contract database. The challenge lies in the enormous amount of data and the need to efficiently identify specific regulatory requirements in different countries.

- Chunking application: Before the analysis, all documents are divided into thematically relevant sections. This enables the LLM to apply its analysis skills specifically to relevant text segments and significantly improve the accuracy of the results.
- Vector database integration: Relevant sections and legal provisions are stored in the vector database. The LLM uses these to retrieve the most relevant legal texts and compliance requirements for specific legal issues.
Download AI knowledge management one-pager
The results are a much more efficient and in-depth analysis of compliance, minimizing regulatory risks and facilitating adaptation to international laws.
Example for the market research department of a large company
A market research department uses LLMs to derive trends and patterns from millions of consumer feedbacks, market reports and social media posts.
- Chunking application: Splitting the data into smaller, thematically focused segments allows LLM to work more precisely and in a controlled context, improving the accuracy of trend analysis.
- Vector database integration: By storing thematic vectors from the analyzed text chunks in the vector database, LLM can consistently and efficiently track relevant topics and trends across a comprehensive and diverse data set.
Download AI knowledge management one-pager

This strategy enables the company to react quickly to changing market conditions and develop customized marketing strategies based on in-depth, data-driven insights.
In both cases, chunking and vector databases prove to be indispensable tools for fully exploiting the strengths of LLMs. Through these techniques, companies can increase the power of AI in text analytics, allowing them to gain deeper insights and make more accurate decisions.
Efficiently manage information floods with AI
In the age of information overload, it is more important than ever for companies not only to manage their data, but also to use it intelligently. With its chunking technology developed in Germany and integration into vector databases, Tucan.ai offers a pioneering solution that emphasizes precision, efficiency, and data protection. Whether it's analyzing complex contracts, identifying market trends or making privacy-compliant decisions, Tucan.ai enables companies to revolutionize their data processing and make informed decisions based on verifiable and accurate data. Discover the transformative power of Tucan.ai and ensure your organization is at the forefront of data-driven decision making.
Manage your knowledge in a precise, scalable and GDPR-compliant way!
Beyond ChatGPT: Pioneering solutions for precise, scalable and secure knowledge management with AI
In today's data-driven world, companies face the daunting task of extracting valuable insights from their vast amounts of data. The use of AI opens up completely new avenues. But when it comes to precisely analyzing a large number of documents, conventional systems such as ChatGPT reach their limits. This is where Tucan.ai comes in, a pioneer in the use of the innovative chunking approach for precise and efficient data analysis. This blog post introduces you to the challenges organizations face when using traditional AI systems and introduces Tucan.ai, which is changing the landscape of AI-powered knowledge management.
Download AI knowledge management one-pager
Table of contents
Problems with common AI systems such as ChatGPT
Given the growing need for companies to use their large amounts of data for intelligent knowledge management, the connection to common AI systems such as ChatGPT has opened up promising prospects. However, this approach poses a number of significant challenges that must not be ignored when planning and implementing such systems.
Risk of AI hallucinations
When connecting company data and databases to common AI systems, such as ChatGPT, there is a risk of so-called AI hallucinations. This means that artificial intelligence generates answers that are not based on real, company-specific data. This erroneous or misleading information can have a significant impact, especially in scenarios where accurate and reliable data is critical for decision-making processes. Companies are therefore faced with the challenge of continuously monitoring and validating the output of such systems in order to avoid incorrect information.
Missing source references
Another shortcoming in the use of common AI systems for knowledge management in companies is the lack of source references in the generated answers. This limitation means that the information provided by the system is difficult to trace and check for accuracy. In environments where data accuracy and reliability are critical, this makes it much more difficult to use such systems to make informed business decisions.
Limitation based on tokens
Common AI systems are subject to limitations in the number of tokens they can process, which leads to problems when connecting to company databases for knowledge management purposes. The token limitation prevents the AI from analyzing and efficiently processing extensive company data in one go. For companies that need to analyze large volumes of text data, this limitation can significantly reduce the usability and efficiency of the AI system.
Data protection in terms of the GDPR
The integration of common AI systems into a company's data infrastructure raises data protection concerns, especially in accordance with the GDPR. Many of these systems train on extensive databases that may contain potentially personal information without the clear consent of the individuals concerned. For companies, this means a legal risk if their AI application does not meet the strict data protection requirements. This requires additional resources to ensure GDPR compliance, including a transparent explanation of how and what data is processed.
Download AI knowledge management one-pager
Tucan.ai: An innovative solution, Made In Germany
With its technology developed in Germany, Tucan.ai represents a pioneering approach in the field of AI-supported knowledge management. By using advanced algorithms for chunking, Tucan.ai transforms the way companies access and analyze their data. This precision-oriented approach enables efficient segmentation of text data into thematically relevant sections, which are integrated into vector databases for transparent and verifiable analysis. Tucan.ai sets new standards for data analysis by focusing on precision, efficiency and data protection.
What is chunking?
At the heart of advanced knowledge management is the concept of chunking, an approach that is increasingly being considered by companies to improve the efficiency and precision of data analysis using AI. Chunking refers to the process of dividing large amounts of text data or information into smaller, thematically relevant units, also known as "chunks". This technique makes it possible to reduce the volume and complexity of data by using only the most relevant sections for analysis and processing.

Significance for businesses
For companies, the use of chunking in AI-based knowledge management systems can have several significant advantages. First of all, it enables targeted analysis of individual data blocks without the AI algorithm being overwhelmed by the wealth of irrelevant information. This not only leads to more precise and relevant results, but also improves the efficiency of data processing. In addition, this approach allows companies to ensure that their AI systems focus on the really important data, which is particularly important when processing sensitive or confidential information.
Increased efficiency in data processing
By dividing data into smaller, thematically coherent blocks, chunking enables targeted processing and analysis. This prevents the system from being overwhelmed by the sheer volume of information, which is particularly important when processing complex or multi-layered data sets. The ability to analyze specific data sections precisely and quickly leads to a significant increase in efficiency in knowledge management.
Improved accuracy and relevance of insights
One of the core problems of large data sets is the identification of relevant information. The principle of chunking enables AI systems to analyze precisely those data blocks that are relevant to a specific query or problem. This leads to more precise answers and insights, as irrelevant information is systematically filtered out. For companies, this means that they can rely on the insights generated to make informed decisions.
Simplifying complex data analysis
The ability to divide large and complex data sets into manageable units simplifies data analysis considerably. This structure makes it possible to carry out in-depth analyses without getting lost in the wealth of data. For fields such as market research, customer analytics or contract analysis, where detailed and specified insights are required, chunking offers a clear advantage.
Improved data protection and compliance
The principle of chunking also makes it possible to control and restrict the processing and analysis of data. This can be particularly crucial with regard to data protection and compliance with regulations such as the GDPR. Companies can be more specific about what data should be analyzed, which minimizes the risk of processing sensitive information without proper authorization.
![]()
Download AI knowledge management one-pager
Chunks in vector databases: Enabling precise source references
The integration of thematic blocks or "chunks" in vector databases is an innovative approach that revolutionizes the way data storage and retrieval works, especially in the context of AI-supported knowledge management. But why is this integration so effective and how does it contribute to accurate source references?
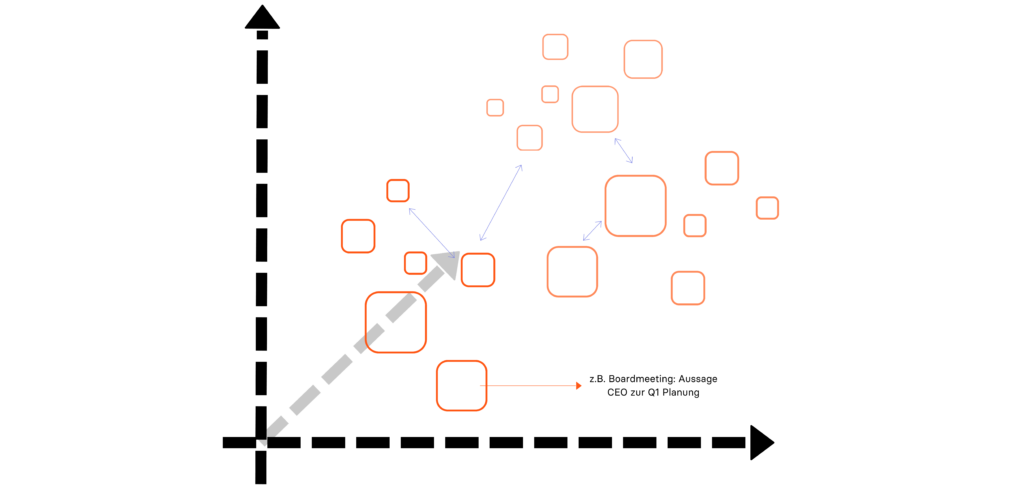
The importance of vector databases
Vector databases store information as vectors, a format that is particularly suitable for analysis and processing by machine learning algorithms. This type of database is ideal for handling high-dimensional data and enables complex queries and analyses at high speed - a significant advantage when searching for specific information within huge data sets.
Connecting chunks and vector databases
By storing chunks as individual vectors in vector databases, AI systems can quickly and efficiently access exactly the data sections that are relevant to a query. This leads to a precise and fast assignment of source references. Each chunk can be provided with specific metadata, including source information, which enables traceable and verifiable data analysis.
Advantages for businesses
1. Increased transparency:
By explicitly assigning sources to the analyzed data segments, the origin of the information becomes transparent, which is crucial for compliance and building trust.
2. Enabling precise source references:
This makes it easier to validate and verify the insights generated by the AI, which is particularly important in areas where data accuracy is critical.
![]()
3. Improvement of data quality and analysis results:
The clear allocation of data to the corresponding sources minimizes confusion and errors that could arise from incorrect or misleading information.
4. Efficient data management:
The ability to access relevant information in a targeted manner without having to search through entire databases saves time and resources.
Download AI knowledge management one-pager
Real-world examples
The variety and breadth of potential applications for chunking in the corporate landscape is enormous. Below you will find two selected examples that merely scratch the surface of this multi-faceted approach and illustrate the transformative power that chunking can have for specific professional requirements.
Contract analyses for lawyers
An outstanding application example of chunking in the corporate environment can be found in legal practice. Lawyers are often faced with the challenge of analyzing extensive contractual documents in order to identify and understand specific clauses, conditions and obligations. By using chunking, contract documents can be divided into smaller units, each of which reflects specific aspects of the contract, such as liability provisions, termination rights or data protection clauses. This enables lawyers to quickly and efficiently access relevant sections and perform comprehensive contract analyses with unprecedented precision.
Analysis of extensive data sets for market researchers
For market researchers faced with the challenge of gaining detailed insights from vast amounts of market data, chunking offers an effective solution. By dividing the data into thematically relevant chunks, the AI can search specifically for trends, patterns and consumer behavior in different segments of the market. For example, data streams from social media, customer feedback and purchase histories can be divided into separate chunks to address specific questions regarding product preferences or buyer demographics. This targeted analysis strategy enables market researchers to make more precise predictions and support well-founded decisions.
Efficiently manage information floods with AI
In an age of information overload, it is more important than ever for companies not only to manage their data, but also to use it intelligently. With its chunking technology developed in Germany and integration into vector databases, Tucan.ai offers a pioneering solution that prioritizes precision, efficiency and data protection. Whether it's analyzing complex contracts, identifying market trends or making privacy-compliant decisions, Tucan.ai enables companies to revolutionize their data processing and make informed decisions based on verifiable and accurate data. Discover the transformative power of Tucan.ai and ensure your organization is at the forefront of data-driven decision making.
Manage your knowledge in a precise, scalable and GDPR-compliant way!
AI as a research assistant: Automated analysis of online community data
In the world of digital market research, online communities are gold mines of valuable consumer data. They offer direct feedback and provide insights into the preferences and behavioral patterns of the target groups. However, analyzing this extensive and diverse data poses challenges for many companies. This is where Tucan.ai comes in and revolutionizes the process of data evaluation - progress that was impressively presented by Florian Polak in the marktforschung.de webinar. In this article, we explain the key points of this innovation and show how Tucan.ai is breaking completely new ground in automated data analysis.
"We know how crucial the transparency and reliability of the results provided by our AI is."
Interview Marktforschung.de with Florian Polak
Managing Director, Tucan.ai GmbH
Edit Content
Edit Content
KI generierte Zusammenfassung von Tucan.ai
Zusammenfassung des Webinars “KI als Forschungsassistentin: Automatisierte Auswertung von Onlinecommunitydaten”
Begrüßung und Einführung
Zu Beginn des Webinars begrüßte Sabrina Gehrmann die Zuschauer und stellte Florian Polak vor, den Mitbegründer und Geschäftsführer von Tucan.ai der zuvor als Produktmanager bei Careship gearbeitet hat. Sie wies darauf hin, dass Fragen während des Webinars über einen speziellen Button gestellt werden können und dass Florian Polak diese im Anschluss beantworten wird.
Vorstellung des Themas
Florian Polak führte in das Thema des Webinars ein, indem er die Bedeutung der KI in der Marktforschung, insbesondere bei der Auswertung von Online Communities, erläuterte. Er betonte, wie Forschungsfragen effizient mit großen Datenmengen in kurzer Zeit ausgewertet werden können und gab einen Überblick über die Funktionen und Vorteile der KI-Technologie in diesem Bereich.
Technischer Exkurs und Präsentation des Systems
Polak präsentierte das von Tucan.ai entwickelte System, das in der Lage ist, aus Texten, Audiodaten und Videos relevante Informationen zu extrahieren und zu verarbeiten. Er ging auf die technischen Aspekte des Systems ein, einschließlich der Verarbeitung und Auswertung von Daten, und erklärte, wie das System mit Herausforderungen wie Halluzinationen von KI und Datenschutz umgeht. Er stellte auch dar, wie das System die Zusammenarbeit mit KI-Technologien optimiert, ohne dass zusätzliche Mitarbeiter benötigt werden.
Anwendungsbereiche und Kundenreferenzen
Polak teilte einige Anwendungsbereiche und Kundenreferenzen mit, um zu zeigen, wie das System bereits erfolgreich eingesetzt wird. Er erwähnte namhafte Kunden wie die Bundeswehr, Telefonica, Porsche, Mercedes und Axel Springer, die das System für verschiedene Zwecke nutzen.
Fragen und Antworten
Im letzten Teil des Webinars beantwortete Florian Polak Fragen der Zuschauer zu verschiedenen Themen, darunter die Anwendung des Systems auf verschiedene Studientypen, Testmöglichkeiten vor der Beauftragung, Vergleiche zwischen Länderstudien, die Mindestmenge an Daten für eine zuverlässige Arbeit des Systems, die Erkennung von Dialekten und Schreibfehlern sowie die Kombination von quantitativen und qualitativen Daten.
Abschluss
Zum Abschluss bedankte sich Sabrina Gehrmann bei Florian Polak und den Zuschauern. Sie wies auf kommende Webinare hin und verabschiedete die Teilnehmer.
Edit Content
KI generiertes Transkript von Tucan.ai
Sabrina Gehrmann: 00:00:07,070 –> 00:00:46,280
Es wartet wieder ein aufregendes Webinar auf uns. Deswegen würde ich sagen höchste Zeit, dass wir jetzt starten und damit. Hallo und herzlich willkommen, liebe Zuschauerinnen und Zuschauer zu diesem Webinar heute hier auf Marktforschung punkt.de. Mein Name ist Sabina Germann. Ich bin hier online Eventmanagerin im Haus und zum heutigen Webinar Ganz herzlich begrüßen darf ich Florian Polak. Er ist Mitbegründer und Geschäftsführer von Tucan.ai. Zuvor hat er bereits als Produktmanager bei Careship gearbeitet. Und nicht nur deswegen freuen wir uns sehr, ihn heute zu begrüßen. Deswegen auch an dich. Hallo Florian, schön, dass du da bist.
Florian Polak: 00:00:47,060 –> 00:00:47,930
Freut mich. Hallo!
Sabrina Gehrmann: 00:00:49,100 –> 00:01:31,460
Und für Sie noch der Hinweis Liebe Zuschauerinnen und Zuschauer, wenn Sie gleich in den nächsten 30 Minuten Fragen haben, dann stellen Sie die sehr gerne. Es gibt unten an Ihrem Bildschirmrand den Button F, A oder K und A. Dort einfach draufklicken, fragen, reinschreiben. Wir haben uns vereinbart, dass Florian alle Fragen dann im Anschluss beantworten wird. Deshalb gerne diese diese Möglichkeit nutzen. Aber jetzt freuen wir uns sehr auf die KI als Forschungsassistentin. Automatisierte Auswertung von Onlinecommunitydaten. Und damit gebe ich auch jetzt an dich ab. Florian, Du darfst gerne deinen Bildschirm teilen und ich wünsche Ihnen, liebe Zuschauerinnen und Zuschauer, jetzt ganz viel Spaß.
Florian Polak: 00:01:33,440 –> 00:02:14,420
Wunderbar. Ich hoffe, alle können den Bildschirm sehen. Sehr gut. Ja. Vielen Dank, dass ihr heute alle so zahlreich angekommen sind. Wie schon erwähnt, waren Pollock mein Name. Ich bin Geschäftsführer und Gründer von zugeneigt. Ich werde Ihnen heute ein paar Sachen zum Thema KI in der Marktforschung, vor allem im Hinblick auf Online Communities erzählen. Grundsätzlich Warum ist uns dieses Produkt oder wir bzw dieses Webinar ihre Zeit wert? Ich werde Ihnen ein bisschen zeigen, wie Forschungsfragen im Prinzip mit vielen, vielen Daten im Prinzip in wenigen Minuten eigentlich ausgewertet werden können. Ich gebe Ihnen ein paar Tipps und Tricks, wie diese KI funktioniert.
Florian Polak: 00:02:14,540 –> 00:02:53,660
Wir werden auch heute einen kurzen technischen Exkurs machen, was ich Ihnen zeige, was technisch unter der Haube eigentlich steht. Und ich werde Ihnen natürlich zeigen, wie Sie mit KI Technologien am besten zusammenarbeiten können, ohne dass das ohne zusätzliche Mitarbeiter im Prinzip deutlich deutlich mehr Studien auswerten können. Die Agenda für heute Ich werde mich kurz und knapp halten und viel Zeit auch noch für fragen zu lassen. Natürlich. Wir machen eine kurze Vorstellung über unser Unternehmen. Ich werde ein bisschen über das Probleme reden, die es grundsätzlich bei den anderen Communities geht. Ich werde auch von bestehenden KI Systemen, also z.B Tee usw was es dafür Schwierigkeiten immer wieder gibt.
Florian Polak: 00:02:54,170 –> 00:03:44,040
Dann werde ich eine kurze Übersicht über die Software geben. Kleine technischen Exkurs, dann Tiere reinschauen, reinschauen wie funktioniert und sich das System und noch ein paar Informationen zum Datenschutz und zu unseren Preisen sein. Dann starten wir ganz kurz zu uns. Ja, wir wurden 2019 gegründet. Es ist ein KI Unternehmen aus Berlin, mittlerweile mit mittlerweile 20 Mitarbeiter. Wir haben uns darauf fokussiert, aus Gesprächen, aber auch Texten relevante Informationen zu extrahieren und zu verarbeiten. Haben dabei auch einen Fokus auf sensible Informationen. Arbeiten auch in anderen Bereichen, aber vor allem natürlich auch in der Marktforschung und bieten da verschiedene Module an, unter anderem qualitative Kodierung, quantitative Kodierung, aber eben jetzt auch online Communities, die man tatsächlich auswerten kann, Produkte sich Inhalte vorstellen werde.
Florian Polak: 00:03:44,060 –> 00:04:25,790
Ist grundsätzlich. Wie können Sie Ihre Forschungsfragen an große Datenmengen stellen, um das System zu verwenden? Als Assistent quasi, denen die relevanten Informationen tatsächlich auswerten kann und Ihnen auch die Referenzen geben kann, zu den Originaltext stellen, sodass Sie sehr, sehr viele Textnennungen, aber auch verschiedene Formate wie Audio, Video oder auch Text tatsächlich mit diesem System auswerten können. Das System ist so aufgebaut, dass es immer zwei Dinge macht Es macht die Auswertung und es gibt Ihnen die Originaltext stellen. Und ich werde auch ein bisschen dazu sagen, wie wie es technisch funktioniert, damit Sie eine gewisse Grundvorstellung haben, wie das System aufgesetzt ist.
Florian Polak: 00:04:26,720 –> 00:05:10,020
Ein paar Referenzen. Wir arbeiten in Deutschland mit einigen großen Unternehmen schon zusammen. Der größte Kunde, den wir haben, ist die Bundeswehr. Aber auch Telefonica, Porsche, Mercedes und Axel Springer sind unsere Kunden. Ohne Communities grundsätzlich sehr wohl einsetzbar. Natürlich in der Praxis, weil es verschiedene Formate und verschiedene Auswertungstechniken kombiniert und natürlich die Möglichkeit besteht, sehr tief reinzugehen und gewisse Fokusgruppen im Prinzip auszuwerten. Der Teufel liegt allerdings im Detail. Es ist natürlich dann die Auswertung nachher zu führen, vor allem der qualitative Teil, aber auch diese Freitagsantworten zu quantifizieren und dann wirklich auszuwerten und ein gesamtheitlichen Überblick über die ganzen Studien durchzuführen.
Florian Polak: 00:05:10,020 –> 00:05:54,180
Das kann sehr, sehr zeitintensiv sein. Und da ist es besonders wichtig, wenn man vor allem eine Mischung hat aus qualitative Auswertung und quantitative Forschung, dass man wirklich diese Ergebnisse möglichst objektiv betrachtet und auswertet. Und das ist natürlich für eine Maschine etwas leichter als für Menschen, ist auch der Grund, warum wir glauben, dass wir tatsächlich als unterstützend hierfür für die Forscher glauben, dass das System, dass ich auch einen qualitativen Mehrwert bringt, grundsätzlich das Hauptthema natürlich. Man kann das natürlich alles manuell machen, wird ja auch seit einigen Jahrzehnten so gemacht. Grundsätzlich ist natürlich zwei Möglichkeiten Entweder man setzt fehlende Mitarbeiter ein oder heuert Externe dazu, um diese Analysen zu führen.
Florian Polak: 00:05:54,180 –> 00:06:31,920
Das ist teuer. Das kostet alles sehr, sehr viel Zeit. Und aus diesem Grunde ist im Prinzip der Punkt, dass wir uns auf diesen Bereich fokussieren, um eben die Auswertung maschinell unterstützt ein bisschen besser zu machen. Ähm, warum wir jetzt nicht einfach Systeme wie zB die verwenden? Es gibt ja mittlerweile auch mehrere KI Technologien, die rausgekommen sind seit zwei Jahren sehr prominent. Natürlich gibt ein paar Risiken, was das was problematisch finde in der Marktforschung tatsächlich zu dieser Auswertung von Studien ist. Eine Thema sind Halluzinationen. Das ist der Begriff im Prinzip, dass diese KI Algorithmen sehr, sehr gut geeignet sind, ihm Antworten zu liefern.
Florian Polak: 00:06:31,920 –> 00:07:12,810
Manchmal sind sie jedoch leider falsch und es gibt sehr, sehr wird sehr, sehr schwierig, wenn man dem System nicht vertrauen kann, wie man das am besten überprüfen kann. Das ist so eines der Hauptthemen hier in der Marktforschung. Das zweite Thema natürlich, wenn man so Unternehmen wie zB die im Prinzip für den Einsatz verwendet, man kriegt wahnsinnig gute Ergebnisse Tatsächlich. In manchen Bereichen jedoch gibt es immer das große Drama, dass diese Daten auch teilweise in die USA übermittelt werden. Insbesondere bei vertraulichen Studien ist das natürlich ein Thema und teilweise gibt es Anbieter, die das Ganze zu Trainingszwecken weiterverwenden, das heißt auch ihre Daten tatsächlich verwenden, um das System zu verbessern.
Florian Polak: 00:07:13,830 –> 00:07:54,600
Das hat ein riesen Nachteil. Natürlich, weil ihre vertraulichen Informationen theoretisch dann in diesen Trainingsdaten entstehen und in einer zukünftigen Variante von diesem Algorithmus möglicherweise als Antworten geliefert werden können. Hauptthema natürlich auch hier die Limitierung auf sogenannte Tokens. Das ist die Art und Weise, wie abgerechnet wird. Das heißt, man kann nur eine gewisse Anzahl an Wörter in diese Systeme reinspielen. Führt auch dazu, dass eben nicht alle die gesamte Studie ausgewertet werden kann, sondern dass aufgebrochen werden muss, was zu Inkonsistenzen für Assistenten führt, uns natürlich dazu führt, dass man deutlich deutlich länger braucht, um das System auswerten zu lassen.
Florian Polak: 00:07:55,290 –> 00:08:48,500
Aber das Hauptthema hier auch die Quellen fehlen. Also nochmal das Thema von der Überprüfung. Man muss einen einfachen Weg haben, diese Ergebnisse schnell überprüfen zu können. Originalzitate sind vor allem natürlich bei Studien sehr, sehr spannend. Und das ist genauso ein Thema, das essenziell für die Auswertung ist. Jetzt kommen wir zu unserem System. Grundsätzlich, Was ich Ihnen heute vorstelle, ist relativ forward. Sie haben die Möglichkeit, verschiedene Daten in das System einzuspielen. Das heißt, wir können Videos machen, wir können Audiodateien, die dann beide jeweils transkribiert werden in Text, aber auch Excel oder Elster Tan können hochgeladen werden in das System und dann können an diese Daten Fragen gestellt werden, die dann beantwortet werden von der KI und ausgewertet Tatsächlich und auch Referenzen geben zu den jeweiligen Originaltext stellen, um diese Überprüfung einfach zu machen.
Florian Polak: 00:08:49,700 –> 00:09:28,340
Ich will Ihnen gleich nachher noch mal erzählen, wie es technisch ein bisschen funktioniert. Wir grundsätzlich akzeptieren jede Art von maschinell lesbaren Text, aber auch eben Audio oder Videodateien, die dann von uns transkribiert werden in Text, damit danach ausgewertet werden kann. Verschiedene Formate, Excls, Dateien oder man kann das auch verbinden mit einer API Schnittstelle direkt mit Ihrem Programm, das Sie verwenden, quasi um diese Online Communities zu tun. Es gibt ein paar Garantien, die wir Ihnen geben können, und das eine Thema ist es, wenn der Antihalluzinations Mechanismus eingebaut haben, dass ihm genau dieses System nur aufgrund Ihrer Daten tatsächlich antwortet und nicht Sachen erfindet.
Florian Polak: 00:09:29,180 –> 00:10:06,590
Das zweite Thema ist, dass wir Ihnen garantieren, wenn Sie mit uns in der Cloud arbeiten, dass diese Daten ausschließlich in Deutschland auf unserem Server verarbeitet werden. Mittlerweile ist unsere Standort in Nürnberg und dort werden alle Daten im Prinzip verarbeitet. Zwei dritte Thema Es wir Mit jedem Kunden, den wir mit dem wir zusammenarbeiten, machen wir einen eigenen Cluster im Prinzip auf. Das bedeutet, dass Ihre Daten ausschließlich für Ihre Auswertung verwendet werden, nicht für Trainingsdaten, es sei denn, Sie geben uns die schriftliche Anweisung, dass wir das System manchmal nachtrainieren können für Ihren Use Case. Das ist allerdings nur, wenn Sie uns im Prinzip explizit anweisen.
Florian Polak: 00:10:07,070 –> 00:10:45,350
Und der letzte Punkt ist Es gibt keine Begrenzung an der Anzahl an hochgeladenen Datenmengen. Also Sie sind da völlig frei. Sie können da wirklich hochladen, was sie wollen, wie das System so aufgebaut ist, dass es trotzdem dieselbe Performance gibt. Egal ob das jetzt Terabyte von Daten sind oder tatsächlich nur ein einzelnes Transkript. Was macht unser System also grundsätzlich technisch? Ähm, wir machen im Prinzip zwei Dinge, um sicherzustellen, dass wir große Mengen an Text im Prinzip aufbrechen können. Hier ist ein Beispiel von einem Transkript. Grundsätzlich geht es auch mit einer Exceldatei. Also jede Art von Text wird so aufgebrochen.
Florian Polak: 00:10:45,950 –> 00:11:38,210
Das macht das System. Der erste Schritt ist, dass wir ein sogenanntes inhaltliches Junking machen. Chucking bedeutet, dass wir unseren Text anschauen und den aufbrechenden Themengebieten. Sprich das System versteht den Kontext eines Satzes und schaut sich an Was ist inhaltlich in diesem Satz gerade genannt? Es schaut sich dann auch nochmal an okay, welche anderen Punkte in diesem Transkript oder in dieser Exceldatei passen noch zu diesem Thema und fügt diese Sachen dann zusammen und macht sogenannte Chunks, also solche Themenblöcke, die dann genutzt werden, um im Prinzip weiterverarbeitet zu werden. Das heißt, wir brechen eigentlich diese großen Datenmengen in digestable Bits, das heißt leicht verdauliche Textblöcke auf, die dann im Prinzip im nächsten Schritt in einer sogenannten Vektordatenbank abgelegt werden.
Florian Polak: 00:11:38,810 –> 00:12:31,550
Sie sind Datenbanksysteme, die sehr gut geeignet sind, Inhalte miteinander zu vergleichen. Was wird da gemacht? Diese Chunks, die wir gemacht haben, also diese Textblöcke, werden umgewandelt in einen mathematischen Wert. Eigentlich. Und dieses System beendet diese ganzen Textblöcke in diese mathematischen Punkte, auf diese Vektorbar datenbank ab. Und wir messen dann eigentlich die Distanz zwischen zwei Textblöcken. Also wie ähnlich sind diese Aussagen sich zueinander? Wenn jetzt also eine Forschungsfrage nachgestellt wird, können Sie diese Anfrage oder auch eine Zusammenfassung haben wollen. Wird das auch umgewandelt in einen sogenannten Junk und dann abgelegt auf dieser Datenbank? Das heißt, wir können dann wissen, welche Textblöcke oder welche Informationen sind relevant?
Florian Polak: 00:12:32,210 –> 00:13:09,660
Um Ihre Frage zu beantworten. Gucken Sie sich technisch, wie das ganze System funktioniert hat ein paar Vorteile. Erstens mal dadurch, dass wir das Aufbrechen in diese Textblöcke, ist das System sehr performant. Ist das auch. Bei sehr großen Studien kriegen sie relativ rasch die Ergebnisse. Und es ist, weil eben wirklich nur diese Textblöcke herangezogen werden, die relevant sind für die Studie. Wir können auch mit einer gewissen Wahrscheinlichkeit sagen Wie relevant ist eine Aussage von einem Studienteilnehmer? Um Ihre Frage zu beantworten, zeige ich Ihnen nachher noch mal ganz gleich und wir können auch eine Rückverfolgbarkeit nehmen, was die keinen nimmt.
Florian Polak: 00:13:09,680 –> 00:13:52,040
Um die Frage zu beantworten, weil wir eben genau wissen, welche Textbausteine herangezogen wurden, um die Frage die Antwort zu formulieren. Finden Sie, und das ist im Prinzip genau dieses Thema, wie man eine inhaltliche Analyse sehr schnell machen kann. Wie würde das jetzt in der Praxis eigentlich für Sie aussehen? Auch schon ein. Ein Beispiel zum Beispiel wäre, dass Sie sagen okay, Sie können einen Ex hochladen, wo Sie Ihre gesamte Studien drin haben mit den verschiedenen Aussagen frei Textnennungen beispielsweise auch teilweise was Transkript schon aufgebrochen. Also Excel, können Sie das Ganze hochladen. Wir akzeptieren teilweise auch SVS Dateien, um im Prinzip das Ganze hochzuladen in unser System, was das System im Hintergrund dann macht.
Florian Polak: 00:13:52,040 –> 00:14:34,670
Das bricht eben diese Aussagen alle auch auf diese Textstelle und legt sie im Prinzip in einer eigenen Vektordatenbank für diese Studie ab. Geht natürlich auch mit einer EBA Schnittstelle, so dass das im Prinzip direkt angedockt ist und sie auf einen Knopf drücken und das rüberspielen. Das müssten wir uns da im konkreten Fall einfach anschauen. Der nächste Schritt ist, dass Sie dann eigentlich auswählen. Okay, welche Studie möchte ich jetzt gerade auswerten, drücken drauf und stellen tatsächlich Ihre Forschungsfragen. Da sind Sie sehr frei, wie Sie die Fragen formulieren. Grundsätzlich, dass das System eben machen wird. Es wird alle relevanten Informationen zusammensuchen, um Ihre Frage zu beantworten, Generiert daraus die Antwort auf Ihr, auf Ihre Forschungsfrage.
Florian Polak: 00:14:35,180 –> 00:15:14,840
Wir können auch tatsächlich so Sachen gemacht werden wie Was haben die weiblichen Teilnehmer dieser Studie tatsächlich zu diesem Thema gesagt? Weil wir können nämlich auch bei da bei diesen Textblöcken gewisse Metadaten hinterlegen, also beispielsweise, dass das jetzt eine Aussage von einem weiblichen Studienteilnehmer war. Das Ganze kann aggregiert werden, wird zusammengefasst und wird Ihnen als Antwort rausgegeben. Und Sie haben die Originaltext stellen, die am relevantesten sind, um Ihre Frage zu beantworten. Das schaut dann so aus Sie haben eine gewisse Relevanz da drinnen, wo Sie dann tatsächlich sehen können, okay, welche Aussagen wahr, hat das System herangezogen. Das ist jetzt hier ein Beispiel, weil das eine sehr kleine Studie war.
Florian Polak: 00:15:14,840 –> 00:16:01,790
Aber grundsätzlich kann das sind das üblicherweise was eingeschränkt auf die best passendsten 50 Aussagen und Sie haben natürlich einen Link direkt zu dieser Stelle. Ob das jetzt ein Transkript ist oder Beziehungsweise eine Stelle in einem Transkript oder ob das tatsächlich ein Excel Pfeil ist, wo Sie dann zu dieser jeweiligen Zelle springen, ist im Prinzip egal. Wir verlinken die Informationen, die Sie grundsätzlich in das System eingespielt haben und Sie haben eine leichte, einfache Möglichkeit, im Prinzip diese Aussagen zu überprüfen, indem Sie einfach über dieses eine Symbol drübergehen und sehen die Originalinformationen zu diesem Thema, zu dieser Aussage, dass je nachdem, was für Informationen da noch drinnen sind, inklusive Metadaten usw, kann man da alles relativ gebündelt navigieren.
Florian Polak: 00:16:02,150 –> 00:16:45,570
Aber das sind die Originaltexte. Das Spannende auch an der Tafel ist eben diese Wahrscheinlichkeit. Sie haben damit eine gewisse Überprüfbarkeit. Wie relevant ist ein Inhalt für die Beantwortung Ihrer Frage, um einfach zu sehen okay, wie gut ist das System in Ihrer Frage zurechtgekommen? Weil wie man Fragen formuliert, macht tatsächlich einen sehr großen Unterschied aus. Ähm, letzter Punkt Wir haben tatsächlich jetzt in den letzten paar Monaten ein paar Tests gemacht. Grundsätzlich ist es möglich, auch mehrsprachige Studien zu führen. Sprich man kann eine Frage auf Deutsch stellen und hat in seinen Daten sowohl französische Teilnehmer, englische Teilnehmer und beispielsweise polnische Teilnehmer.
Florian Polak: 00:16:45,570 –> 00:17:31,010
Dass man tatsächlich eine konkrete Studie gemacht haben, die das System übersetzt dann die Originalantworten der Teilnehmer automatisch in die Sprache, in der sie die Frage gestellt haben, gibt Ihnen dann die Antwort raus, basierend auf dem und verlinkt aber die Originaltext stellen dann in der jeweiligen Sprache, sodass Sie im Prinzip diese Studie auch tatsächlich mehrsprachig führen können. Ähm, hier, wir haben. Ich muss dazu sagen, wir haben nicht alle Teilsprachen getestet, die ich oben angeschrieben habe, Haben wir getestet. Bei denen wissen wir, dass es funktioniert. Im Regelfall würde ich sagen, romanische Sprache funktionieren tendenziell ein bisschen besser. Wir haben es noch nicht getestet mit beispielsweise Chinesisch, schlicht und einfach, weil wir auch intern nicht die Leute haben, die sie überprüfen können.
Florian Polak: 00:17:31,340 –> 00:18:12,000
Das heißt, das wäre ein Thema, wo wir uns das anschauen müssten. In Theorie sollten auch mehrere Sprachen eigentlich möglich sein, außer die genannten hier bei der Spracherkennung sind wir auch auf diese Sprachen mittlerweile eingeschränkt. Aber natürlich, wenn Sie schriftliche Daten hier einspielen und zum Beispiel chinesische Umfragen gemacht haben, müssten wir uns anschauen, wie gute Ergebnisse sind. Am besten natürlich mit jemandem, der Chinesisch kann. Natürlich können Sie das kombinieren mit anderen Produkten, die wir haben. Also als Beispiel Wir bieten ja im Prinzip quantitative Kodierung an, dass sie im Prinzip diese Freitagsnennungen zuerst tatsächlich kodieren, diese Ergebnisse dann anreichern, damit und später dann das Ganze noch mal auszuwerten.
Florian Polak: 00:18:12,330 –> 00:18:56,990
Man kann natürlich Kombinationen von dem machen, genauso gut natürlich in der qualitativen Auswertung. Wir haben ja Transkriptionen, bieten wir natürlich auch an und nachher auch noch die Möglichkeit, Aussagen aus Texten zu extrahieren und dann gebündelt als Geschenk so vorzubereiten, dass man es im nächsten Schritt mit solchen Sachen tatsächlich noch weiter auswerten kann. Datenschutz ist natürlich auch ein sehr, sehr wichtiges Thema. Grundsätzlich, wie vorhin erwähnt, Wir garantieren Ihnen, dass die Daten ausschließlich in Deutschland verarbeitet werden. Grundsätzlich Wir verarbeiten die Daten so, wie Sie das wünschen. Es gibt auch noch einmal die Möglichkeit, natürlich einzustellen, wann automatisch Daten wieder aus dem System gelöscht werden, wann im Prinzip was mit den Daten nachher passieren soll.
Florian Polak: 00:18:57,350 –> 00:19:42,770
Da sind wir sehr, sehr frei und je nachdem, wie der Kunde das möchte, können wir uns da natürlich anpassen. Ja, auf individuellen Wunsch. Was wir auch noch anbieten, sind unsere Server in Deutschland. Aber das hatten wir schon einmal, dass wir auch unseren Server in einem anderen Land aufgebaut haben. Schlicht und einfach, wenn der Kunde das gebraucht hat. Aus Datenschutzgründen. Ist möglich, ist aber ein Thema, wo wir einfach drüber sprechen müssen. Grundsätzlich gibt es zwei mögliche Pakete. Das eine Paket, das wir machen, was sehr viel in der Marktforschung verwendet, ist das On Demand Paket. Das heißt, Sie zahlen tatsächlich nach Menge der Datensätze oder pro Projekt, sind damit an keine Bindung gebunden und können das im Prinzip ad hoc nutzen, wann immer Sie, wann immer Sie das brauchen.
Florian Polak: 00:19:43,160 –> 00:20:24,840
Oder das Premiumprodukt, wo Sie sagen okay, Sie haben einen jährlichen Fixpreis, da ist es uns auch egal, wie viele Studien drüber laufen. Sie haben natürlich damit auch noch mal deutlich Mehrwert, weil sie im Prinzip Rabatte bekommen und natürlich noch mehr Service als im On Demand Bereich. Das wollte ich schon vorher erwähnt grundsätzlich die Transkription und nach aber auch die Auswertung. Die qualitative ist natürlich bei jeder Art von ON, von Sprachdaten bzw Videodaten natürlich auch relevant, dass sie diese Sachen in Text umwandeln können, um das Ganze nachher abzuwandeln. Das war’s auch schon von meiner Seite. Jetzt würde ich vielleicht auch die Fragen kurz eingehen.
Florian Polak: 00:20:24,990 –> 00:21:07,110
Ich habe so ein paar Sachen schon gesehen. Wunderbar. Die erste Frage war Beschränkt sich das System auf die Auswertung von allen Communities oder ist möglich eine Kombination zu buchen aus Auswertungen von anderen Communities, Communities bzw Auswertung, offene Nennung aus qualitativen Fragen mit quantitativen Fragebögen? Ja, das ist möglich. Also grundsätzlich das System ist geeignet, wirklich den letzten Schritt zu machen, wenn Sie die Daten schon vorbereitet haben. Sie können unser anderes Modul verwenden, wo Sie im Prinzip tatsächlich beispielsweise Sie haben Interviews, diese Interviews transkribieren, dann über unser qualitatives Codierungsstool im Prinzip aufzubrechen in die jeweiligen Kernaussagen und dann im Prinzip das Ganze auszuwerten.
Florian Polak: 00:21:07,110 –> 00:21:56,280
Das ist möglich, kann man auf jeden Fall machen. Ist es möglich, vor der Beauftragung einen Test Case zu machen? Ja, Sie können das natürlich ausprobieren. Sehr gerne. Kontaktieren Sie mich dazu einfach. Der erste Test ist natürlich kostenlos. Kann das System bei mehr Länderstudien auch Vergleiche zwischen den Ländern ziehen? Ja, geht auch. Man muss sich dazu nur überlegen, wie man das Ganze strukturiert, also im Hintergrund. Wie wir das machen, ist, wenn Sie eine Studie hochladen, werden wir das im Prinzip in einen anderen Ordner im System ablegen. Und dann können Sie sich aussuchen, was tatsächlich Entweder, dass Sie nur gegen diese beispielsweise französische Studie Fragen stellen, oder wenn Sie Vergleichen machen wollen, nehmen Sie sowohl den Ordner mit der französischen Studie oder der deutschen Studie und stellen vergleichende Fragen gegenüber diesen Zahlen.
Florian Polak: 00:21:56,730 –> 00:22:37,970
Geht alles, müsste man nur strukturell sich überlegen, wie man das am besten aufsetzt. Können wir gerne unterstützen, um so was zu machen? So, dann war im Chat noch ein paar Sachen. Wie viele Informationen ausholen, benötigt das System mindestens um zuverlässig arbeiten zu können. Grundsätzlich ist schwer zu sagen, das kann man wahrscheinlich nicht so wirklich kontrollieren. Das heißt, ich würde da einfach sagen grundsätzlich, man kann eine Aussage hochladen und dann eine Frage dagegenstellen. Das ist wahrscheinlich nicht besonders sinnvoll. Aber sie sind ja nicht eingeschränkt. Das heißt, das System wird halt mit entweder zum Beispiel einem Transkript arbeiten oder halt sehr, sehr vielen Excel Daten und Antworten.
Florian Polak: 00:22:38,450 –> 00:23:27,730
Da kommt ein bisschen darauf an, je mehr Daten Sie natürlich einspielen, ein System, desto wahrscheinlich statistisch relevanter ist das Kann ich nicht selber beurteilen. Müsste man sich einfach den konkreten Fall anschauen? Was verbirgt sich hinter dem Relevanzwert, der das System für vergibt? Wie ist diese zu verstehen? Sehr gute Frage. Grundsätzlich Was ist diese Relevanz? Das ist die Distanz, die mathematische von diesem in dieser Vektordatenbank. Zu Ihrer Frage Das heißt, wenn wir noch mal zurückgehen. Wie weit ist diese Aussage von diesem Studienteilnehmer? Von der Distanz her weit entfernt, inhaltlich weit entfernt von Ihrer Frage. Das ist das System Im Prinzip, das die Relevanz misst, ist ein Prozentueller Wert, den man dann mathematisch ganz gut ausrechnen kann.
Florian Polak: 00:23:28,090 –> 00:23:56,830
Aber das ist im Prinzip genau dieser Aspekt, der technisch funktioniert, um. Um das im Prinzip zu mappen. Das heißt, im ersten Schritt wird das Ganze, wie gesagt mathematisch umgewandelt und dann wird einfach die Distanz gemessen, um diese Relevanzwerte benennen zu können. Finde ich die Aufzeichnung später irgendwo für die Chefs. Danke. Ja, ich kann Ihnen auch gerne die natürlich im Anschluss die Präsentation schicken Aufzeichnen auf Marktforschung. Punkte Eens müssten die Kollegen dann beantworten.
Sabrina Gehrmann: 00:23:57,520 –> 00:24:04,810
Genau. Das Ganze wird aufgezeichnet. Das packen wir später bei uns in die Mediathek. Deswegen. Das können Sie alles noch mal nachschauen.
Florian Polak: 00:24:05,960 –> 00:24:54,570
Noch werden Dialekte und Schreibfehler erkannt und gehen diese Infos dann verloren. Also grundsätzlich. Das System ist relativ robust, was Schreib oder Grammatikfehler angeht. So, wenn es. Ausreicht, um den Kontext aus diesem Satz oder diesem Absatz zu extrahieren, würde es das System richtig zuordnen. Da kann es natürlich manchmal Fehler geben, je nachdem, wie diese Sachen formuliert sind. Wir kennen sehr gut mittlerweile aus der quantitativen Kodierung, wo natürlich haufenweise Grammatik und Rechtschreibfehler drinnen sind. Üblicherweise ist es so, dass es erstaunlich viele erkennt. Können wir natürlich gerne in einer Probe Testlauf einfach mal ausprobieren. Können Sie gerne auch mit vielen Rechtschreibfehlern und Grammatik Fehlern das einspielen lassen?
Florian Polak: 00:24:54,840 –> 00:25:31,350
Sie werden sehen, dass das System eigentlich das ganz gut erkennen könnte. Wunderbar. Und Dialekte? Ja, für Dialekte kann ich Ihnen ist vor allem relevant in der Spracherkennung. Da können wir uns fokussieren auf möglichst vor allem deutsche Dialekte und Akzente gut zu können. Ich selber bin Österreicher, wie Sie es vielleicht hören. Also auch österreichische Akzente gehen grundsätzlich ganz gut. Ich würde sagen, je weiter westlich man geht, also Richtung der Schweiz, desto schwieriger wird es. Wir haben tatsächlich noch massive Probleme in der Spracherkennung. Nicht nur wir, sondern alle. Leider. Um die Schweizer zu verstehen. Also Schweizerdeutsch ist noch ein ungeklärtes Thema.
Florian Polak: 00:25:31,770 –> 00:26:08,130
In geschriebenen Texten ist es dann tatsächlich ein bisschen einfacher. Wiederum, weil da einfach wiederum das System einfach versucht, den Kontext aus diesem Satz zu erkennen. Im Regelfall sollte das ein bisschen besser funktionieren. Schweizerdeutsch haben wir auch da aber noch nicht getestet. Das müsste man schauen. In Ihrer zitierten Studie Welche oder wie viele Daten hatten Sie hierfür? Das war Ich kann es nicht auswendig sagen, aber ich glaube, wir hatten auf jeden Fall Aussagen von über 200 Teilnehmern. Das waren an sich eine große Studie, die wir da hatten. Das heißt, es war. Es war eine Excel Datei, alle waren schön gemischt, also hatten wir im Prinzip viel Text Antworten auf.
Florian Polak: 00:26:08,310 –> 00:26:44,670
Ich glaube, es waren über 50 Fragen. Es ging über mehrere Tage. Das Ganze, teilweise auch Audioaufzeichnungen von den Teilnehmern, die dann transkribiert wurden und auch noch einmal eingespielt würden. Also es war schon eine ziemliche Monsterstudie, die wir da gemacht haben und auf verschiedenen Sprachen wurde das Ganze ausgewertet haben. Aber auch Ihr Vorschlag Probieren Sie es einfach gerne mit uns aus. Sie haben meine Kontaktdaten. Jetzt können Sie jederzeit gerne schreiben. Wir können gerne eine Probe Durchlauf machen und noch einmal im Detail schauen, ob das für Ihre Studie geeignet ist. Und wir können das gerne einfach mal ausprobieren.
Florian Polak: 00:26:46,050 –> 00:27:21,230
So, und ich habe jetzt gleich noch ihm Fragen und Antworten. Gibt es noch was? AT the dam. Wie sieht es mit der Auswertung von quantitativen Daten in Kombination mit qualitativen Aussagen und Fragebögen an? 50 % der Befragten fanden XY nicht so gut und den offenen findet man dann eine Erklärung, warum das so ist. Das ist tatsächlich ein sehr gutes Beispiel, wo es gut funktioniert mit dem System, weil wir dann den Konnex zwischen diesen beiden Fragen herstellen und dann auch die Aussage miteinander kombinieren können. Tatsächlich, das ist auch der Bereich, wo das Ganze recht spannend wird. Können wir gerne ausprobieren.
Florian Polak: 00:27:21,410 –> 00:28:08,570
Mein Vorschlag wäre Kontaktieren Sie uns einfach und wir können das einfach mal testen. Welche Übersetzungssoftware ist integriert? Grundsätzlich. Teilweise geht es sogar mit den mit der KI selber. Dass die vom Kontext her viel verschiedenen Sprachen versteht, einfach aufgrund der Trainingsdaten, die da drinnen sind, ist in vielen verschiedenen Sprachen drinnen. Wir haben unterstützend auch noch die BL, die meiner Meinung nach eigentlich die besten Übersetzungen und Übersetzungsmodule hat, aber grundsätzlich im Regelfall auf textueller Ebene ist das System tatsächlich meistens sogar schlau genug, tatsächlich das Ganze miteinander zu übersetzen und den Kontext daraus zu verstehen. Kommt darauf an, wir würden die Bälle dann zuschalten, wenn wir sehen, dass der Kontext nicht herausgelesen werden kann.
Florian Polak: 00:28:08,900 –> 00:28:23,430
Das wäre zum Beispiel eine Möglichkeit, wenn man Sprachen hat wie Chinesisch oder Arabisch, die doch sehr, sehr anders sind. Dann würden wir wahrscheinlich auf die Welt zurückgreifen. Ein noch. So? Ich glaube, das war’s, oder?
Sabrina Gehrmann: 00:28:24,150 –> 00:29:09,000
Ja. Erfolgreich. Alle Fragen beantwortet. Deshalb vielen lieben Dank, Florian, dafür. Und ich denke, wenn Sie noch Fragen im Nachgang haben, hier sind ja die Kontaktdaten. Deswegen gerne einfach melden. Deswegen würde ich unter die Kühe und als Häschen jetzt einen Strich machen und möchte Ihnen, liebe Zuschauerinnen und Zuschauer und natürlich auch Florian noch den Hinweis geben, dass wir Ende, oder? Ja, ab Mitte Februar stehen weitere spannende Webinare bei uns im Haus an, da können Sie sich einfach wieder anmelden. Alles kostenfrei, versteht sich. Auf dem gewählten, gewohnten Weg über Marktforschung punkt.de unter der Rubrik Webinare. Dort gerne einfach mal reinklicken.
Sabrina Gehrmann: 00:29:09,000 –> 00:29:32,010
Da würde ich mich freuen, den oder die eine oder andere noch wieder begrüßen zu dürfen. Zum nächsten Event. Ja, aber jetzt würde ich sagen, haben wir es auch geschafft für den Vormittag und entlassen gleich alle in die Mittagspause. Bevor du gerne die Schlussworte wählen darfst, sage ich von meiner Seite aus schon mal vielen lieben Dank für Ihre Aufmerksamkeit, liebe Zuschauerinnen und Zuschauer und wünsche gleich eine schöne Mittagspause.
Florian Polak: 00:29:33,080 –> 00:29:34,600
Gut. Vielen Dank. Danke schön.
Sabrina Gehrmann: 00:29:35,470 –> 00:29:35,860
Tschüss.
Online community data - an ocean of insights
The true value of online community data lies in its ability to provide deep insights into the minds of consumers. This data goes far beyond quantitative statistics and includes qualitative elements such as free text responses and multimedia content, enabling a holistic analysis. The challenge lies in the complexity and diversity of this data, which requires efficient and effective analysis.
Tucan.ai: Redefining data analysis
Tucan.ai enables market researchers to process online community data as a whole. Using specially developed AI algorithms, Tucan.ai can transcribe and analyze text, video and audio content in just a few minutes. The USP lies in the combination of versatile data processing, precise analytics, and data security. The AI-powered platform is specially designed not only to capture complex data volumes quickly but also to analyze them in-depth, contextually, and with source references for the answers. The insights generated in this way enable more informed decisions and give companies a significant competitive advantage in a competitive market environment.

Efficiency paired with in-depth analysis
Tucan.ai's technology is designed to deliver results quickly without sacrificing relevance and accuracy. The key to this is Tucan's ability to process large volumes of text data efficiently. By breaking up the texts into smaller, thematically related blocks (so-called "chunks") and using a vector database, Tucan can quickly identify relevant information and use it to answer research questions. This process makes it possible to analyze the data thoroughly and efficiently without resorting to the generation of non-existent information.
Transparent and reliable results, without AI hallucination
An important feature of the software is the source referencing of each generated response. This ensures a high level of transparency in the evaluations and strengthens confidence in the reliability of the AI analyses. Tucan.ai also ensures that the AI only generates answers based on the data fed in and does not rely on external data or inventions. A crucial detail, especially when it comes to confidential and precise evaluations.

No limit to data volumes
Another advantage of Tucan.ai is that there is no limit to the amount of data that can be uploaded. Regardless of whether gigabyte or terabyte - the system performance remains unchanged.
Data security and GDPR-compliant
Security and data protection are very important, especially when it comes to sensitive research data. One guarantee that Tucan.ai offers is that the data is processed exclusively on servers in Germany. This gives companies the confidence that their data will be handled in accordance with the GDPR.
Competitive advantage with AI
Using Tucan.ai in projects means that market researchers no longer have to burden themselves with the tedious task of analyzing data. Instead, they can use their expertise to gain deeper insights and make strategic business decisions. This reorganization of resources allows companies to work on more projects at the same time and expand their capacities.
Tucan.ai is a glimpse into the future of market research, in which the automation and intelligent analysis of online community data can help companies gain enormous competitive advantages. The combination of technology, user-friendliness and precision makes Tucan.ai an indispensable tool in modern market research.